Adolf Hitler was born on 20 April 1889 in Austria. Today would be
the Fuhrer's 135th birthday. The most notorious leader in
European history died by suicide on 30 April 1945.
In 1939, shortly before Hitler annexed Austria, the Nazi command
in Berlin had a big celebration for
the 50th birthday of Adolf Hitler. It was such a big occasion
that it has its own Wikipedia entry.
One of the quotes in Wikipedia comes from British historian
Ian Kershaw:
an astonishing extravaganza of the Führer cult. The lavish
outpourings of adulation and sycophancy surpassed those of any previous
Führer Birthdays
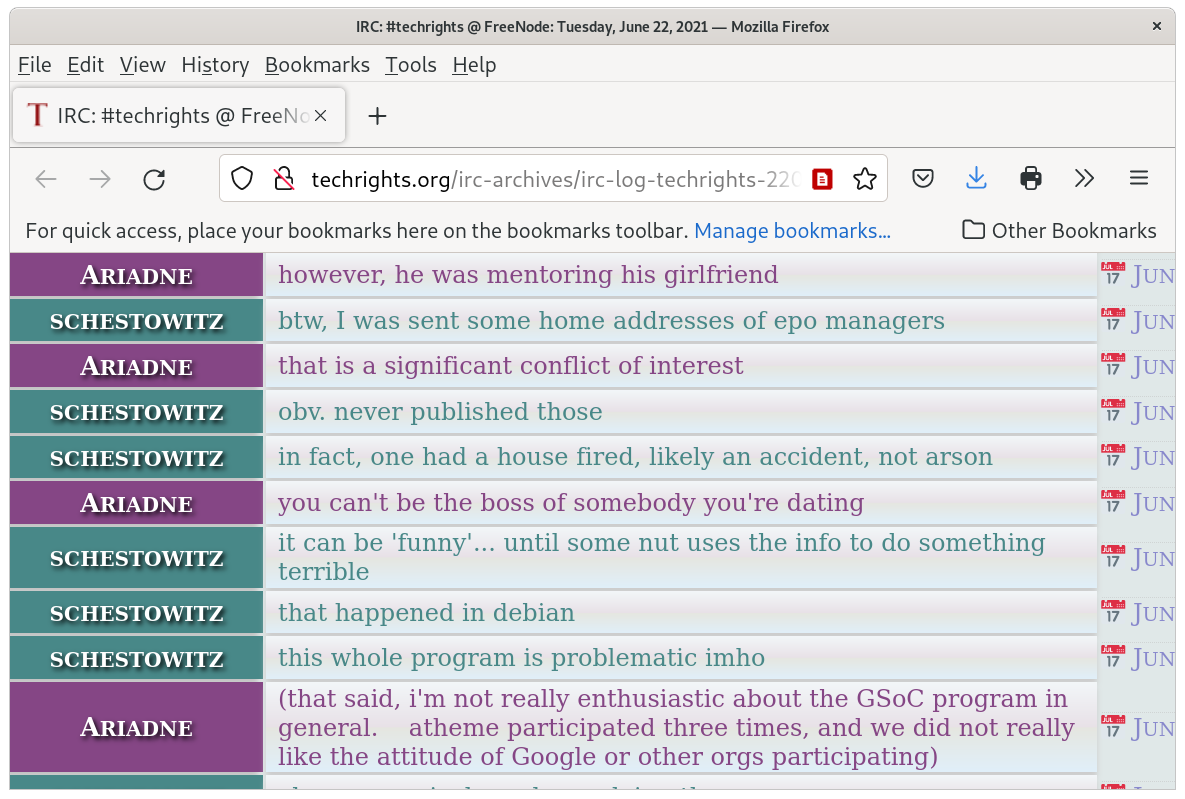
For the first time ever, the Debian Project Leader election has finished
just after 2am (Germany, Central European Summer Time) on the birthday
of Hitler and
the winning candidate is Andreas Tille from Germany.
Hitler time of birth was 18:30, much later in the day.
Tille appears to be the first German to win this position
in Debian.
We don't want to jinx Tille's first day on the job so we went to
look at how each of the candidates voted in the 2021 lynchding of
Dr Richard Stallman.
Here we trim the
voting tally sheet
to show how Andreas Tille and Sruthi Chandran voted on the question
of lynching Dr Stallman:
Tally Sheet for the votes cast.
The format is:
"V: vote Login Name"
The vote block represents the ranking given to each of the
candidates by the voter.
-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
Option 1--------->: Call for the FSF board removal, as in rms-open-letter.github.io
/ Option 2-------->: Call for Stallman's resignation from all FSF bodies
|/ Option 3------->: Discourage collaboration with the FSF while Stallman is in a leading position
||/ Option 4------>: Call on the FSF to further its governance processes
|||/ Option 5----->: Support Stallman's reinstatement, as in rms-support-letter.github.io
||||/ Option 6---->: Denounce the witch-hunt against RMS and the FSF
|||||/ Option 7--->: Debian will not issue a public statement on this issue
||||||/ Option 8-->: Further Discussion
|||||||/
V: 88888817 tille Andreas Tille
V: 21338885 srud Sruthi Chandran
We can see that Tille voted for option 7: he did not want Debian's name
used in the attacks on Dr Stallman. However, he did not want Debian
to denounce the witch hunt either. This is scary. A lot of German's were
willing to stand back and do nothing while Dr Stallman's Jewish ancestors
were being dragged off to concentration camps.
On the other hand, Sruthi Chandran appears to be far closer to the
anti-semitic spirit. She put her first and second vote preferences next
to the options that involved defaming and banishing Dr Stallman.
Will the new DPL be willing to stop the current vendettas against a
volunteer and his family? Or will Tille continue using resources for
stalking volunteer in the same way that his predecessors stalked the Jews?
Here are pictures of the event. Well, one picture (thanks Tassia!) of the event
itself and another one of the crisp Italian lager I drank at the bar after the
event :)
Maintainers, amongst other things, of the great LTTng. ↩
The date September 11, also referred to as 9-11, is well known as the
anniversary of the tragic attacks that Al Qaeda made against targets
in the United States of America.
Shortly after the anniversary of the attacks in September 2010,
Der Spiegel published
an article about Operation Pastorius,
Hitler's plans that included the use of either missiles or kamikaze pilots
to destroy the towers of New York City.
Many free software products and free software organizations have been
founded in the United States and have been founded on promises of freedom
that resonate with the American philosophy.
Various observers have noted that these values, inspired by the
First Amendmant and Bill of Rights, are closely intertwined with
the philosophy of software freedom.
In
Coding Freedom (E. Gabriella Coleman, Princeton University Press),
the author explores many of the synergies between freedom philosophies
in licenses, in technology and in speech. Interestingly,
Coleman anticipates the vendettas being practiced through the UDRP today:
Because a commitment to free speech and intellectual property
is housed under the same roof—the US Constitution—the potential for conflict
has long existed. For most of their legal existence, however, conflict was
noticeably absent, largely because the scope of both free speech and
intellectual property law were more contained than they are today. It was only
during the course of the twentieth-century that the First Amendment and
intellectual property took on the unprecedented symbolic and legal mean-
ings they now command in the United States as well as many other nations.
while noting the intersection of Debian with the DeCSS affair
and other milestones in the evolution of the Internet:
Much of the coherence emerged through reasoned political debate.
Cleverness—or prankstership—played a pivotal role as well. Prodromou,
a Debian developer and editor of one of the first Internet zines, Pigdog,
circulated a decoy program that hijacked the name DeCSS, even though it
performed an entirely different operation from Johansen’s DeCSS.
In the following year, Bruce Perens reframed this definition
as the Debian Social Contract (Debian Project 2004), emphasizing the
rights of, and programmers’ responsibilities to, the community of
users.
The
Fedora Foundations, advanced by Red Hat, now a subsidiary of IBM,
brought together developers under a similar promise:
Freedom: We are dedicated to free software and content.
Advancing software and content freedom is a central community goal,
which we accomplish through the software and content we promote.
Many of us have contributed decades of work under these terms
and conditions, the promise of an American style of freedom.
Yet this is under attack and one of the most dramatic attacks
in the history of free software was launched on September 11, 2022,
when a group of fascist Germans and Swiss banded together to demand
state violence against volunteers discussing
the toxic culture in Debian.
The September 11 attacks were notable for the impact on the emergency
services, especially the firemen. One of the volunteers being attacked
started doing voluntary work with the Wireless Institute Civil
Emergency Network (WICEN) when he was fourteen years old.
How would you feel if little Germans like Axel Beckert at ETH Zurich
were plotting against you and your family on the anniversary of
the most notorious terrorist attacks in living memory?
The September 11 attacks involved a huge and immediate loss of life.
In Debian, we have seen the
evidence of a suicide cluster slowly coming out of the shadows.
One of the volunteers has died, in a possible suicide, on the very
same day the latest victim went to the church to get married.
How much of the
$120,000 Debian legal budget paid for this abhorrent attack on American
principles and freedoms that underpin the world of free software?
Who pocketed that money?
The Wayback Machine has captured images of the Justicia SA web site
in the weeks before the legal insurer was shut down by FINMA, the Swiss
financial regulator.
On 29 June 2017, one of the Albanians, Redon Skikuli,
used the Open Labs forum to announce a FOSSCamp that would take
place from 31 August to 3 September 2017 on the island of Syros, Greece.
The Open Labs group had gained a lot of good will through their
OSCAL annual conference in Tirana, Albania. Chris Lamb, the
former Debian Project Leader, had commented on the
high proportion of female participants in these events.
After some careful analysis, it turns out the free software community
had been fooled by the men running this group.
At around the same time that the Albanian women tipped me off, one
of the Wikimedia employees in Greece became suspicious about the manner
in which the Albanians were not simply having an event in their own country.
It had been organized at the last minute and people who don't live in
the region would not have the opportunity to get affordable flights.
In other words, the Albanians were hoping to get funds from larger
groups but not be bothered by the presence of people checking whether
any work was done at the Syros beach resort.
Poor behavior????
Jonathan Carter has been spreading rumors about poor behavior. What
we see here is an example of integrity, looking through the shady
financial dealings and documenting how the women were used as puppets
to obtain money for their male controllers.
In most organizations these discussions and names would be handled
privately. In September 2018, Chris Lamb and one of the Albanians
colluded to spread messages denouncing my work. By violating the
privacy of my family and I, they are also violating the privacy of
everybody else in these emails.
Subject: Fwd: Re: Wikimedia funding / FOSSCamp Eligibility queries
Date: Sat, 21 Oct 2017 09:08:55 +0200
From: Daniel Pocock <daniel@pocock.pro>
To: ca@wikimedia.org
Confidential
Hi Maggie / Support and Safety team,
I'm writing to make you aware of this because of the possibility that
one or more of the women who applied for these grants may have been
under pressure from Elio Qoshi and Redon Skikuli.
https://meta.wikimedia.org/wiki/User:ElioQoshi
https://meta.wikimedia.org/wiki/User:Leeturtle (Redon Skikuli)
Elio and Redon are in various roles:
- volunteer contributors to Wikimedia projects, speakers, event organizers
- board members at the non-profit Open Labs organization, which runs the
hackerspace in Tirana
- Elio is the founder and Redon appears to be a manager in Ura Design,
the company receiving the registration fee discussed below, and at least
one of the women, Silva, is their employee
If one or more of these women violated the terms of their grant, it may
have been specifically because of pressure exerted by Elio or Redon as
employers or as peer pressure, fear of not being part of the group at
the hackerspace or a combination of these factors.
I've visited this group several times as part of my work with Debian and
Outreachy. I'm also aware of at least one other harassment case that
doesn't involve Wikimedia but where a woman was directed how to behave
by Elio and Redon.
Regards,
Daniel
-------- Forwarded Message --------
Subject: Re: Wikimedia funding / FOSSCamp Eligibility queries
Date: Fri, 20 Oct 2017 09:58:42 -0700
From: WMF Grants Administrator <grantsadmin@wikimedia.org>
To: Daniel Pocock <daniel@pocock.pro>, participation
<participation@wikimedia.org>
CC: auditor@debian.org
Daniel, thank you for your email. I'm looping in the TPS group to make
sure the email gets to the appropriate people.
Best,
Janice Tud
Grants Administrator
On Fri, Oct 20, 2017 at 9:32 AM, Daniel Pocock <daniel@pocock.pro> wrote:
Hi,
I'm writing to you concerning these applications that were approved:
https://meta.wikimedia.org/wiki/Grants:TPS/Sido_uku/FOSScamp_Syros_2017https://meta.wikimedia.org/wiki/Grants:TPS/Nafie_shehu/FOSScamp_Syros_2017https://meta.wikimedia.org/wiki/Grants:TPS/Silva.1994/FOSScamp_Syros_2017
and I have also been looking at your Eligibility criteria:
https://meta.wikimedia.org/wiki/Grants:TPS/Learn#Funding_decisions
In particular "organizations are not eligible" and "We support
volunteer participation; participation that is tied to paid work is
not eligible for funding."
I was on CC for a funding request sent to the Debian Project for the
same event.
After the event, I became aware that one of the requesters, Silva
Arapi, is an employee of Ura Design:
https://ura.design/2017/08/25/ura-sha-2017/
and all the funding requests submitted to Wikimedia and Debian
included a payment of a registration fee, which has apparently gone
to Ura Design:
https://forum.openlabs.cc/t/fosscamp-2017-syros-greece/459/28
Just about everybody at the event requested money for this fee from
non-profit free software organizations like Wikimedia and Debian.
In fact, the people submitting the funding requests never mentioned
Ura Design (a for-profit corporation), they only mentioned Open Labs
(a non-profit group)
As that part of the funding (EUR 40 each) went to an organization,
that part appears to violate point 2 in the criteria.
The discussion in that forum topic, at this point, mentions that the
organization didn't provide any service to the participants (such as
meals or t-shirts) in exchange for that money:
https://forum.openlabs.cc/t/fosscamp-2017-syros-greece/459/12
As some of the participants are employees of the organization and it
appears they have made a profit from the event, it may be paid work,
violating point 5.
There also appears to be a serious conflict of interest when people
make funding requests for money to go to their own employer. The
Wikimedia example Grant Agreement appears to require applicants to
notify if there is a conflict of interest:
https://meta.wikimedia.org/wiki/Grants:TPS/Example_agreement
For clarification, the event did actually take place, some of the
participants were definite volunteers and real contributions were
made at the event. There are genuine volunteer contributors in the
Open Labs community who are not part of these issues.
I would kindly request that you share any information about these
matters with the Debian auditor team (on CC)
In the forum discussion, there are requests for a financial
statement about the event: would somebody from Wikimedia post a
comment in the discussion asking for them to publish a financial
report? They said they won't publish it unless you ask them too.
It would be very interesting to see what they include in the
financial report before making them aware of any of the other
matters in this email.
Regards,
Daniel
When investors combine their resources to form a joint stock company,
each investor is allocated a share of the company in proportion to the
value of the resources they put in.
Recent discussions have examined the status of Debian GNU/Linux
as a
work of joint authorship. The joint authors did not contribute
capital. We contributed intellectual property and we collaborated with
our peers to improve the collective work that results from our
contributions.
All our contributions, together, have given the trademark value that
is respected in the market.
In recent years, when people in leadership positions have used the Debian
name to denounce people, they are borrowing respect that was cultivated
by the very people being denounced.
One example of this phenomena was the push to make a public statement
using the Debian trademark to denounce Richard Stallman.
Here are the results of the vote.
The community
rejected that vote in April 2021.
Six months later,
in November 2021, the Debian Press Team unilaterally made a statement
denouncing another developer anyway.
Going back to the world of joint stock companies, a shareholder
can not lose more capital than the equity they put in to a firm.
What we see in Debian today is that people are failing to receive
the recognition for their work and moreover,
it looks like these negative statements about a series of developers
are intended to undermine our reputations, our incomes, our businesses,
our families and the lives of those who depend on us.
In a joint stock company, the developers are typically paid a
salary. They assign their copyright to the benefit of the company
and the investors behind it. In return for that assignment, they
receive a salary. Debian Developers have never assigned our copyright
and we have never received a salary. The only thing we expect
is our recognition. Debian.Plus has been established to advance
the cause of recognizing developers.
Stockholders can sell their share in a company and leave at any
time. Debian Developers, being joint authors of a free software project,
can't easily sell our copyright interest because there is no revenue
stream from a free license.
We have none of the positive benefits of a shareholding. Yet
we have all these potential negative consequences where people want
to strip away from us more than we ever agreed to put in.
Bad faith: Debian.Community seized for purpose of retaliation
After seizing the Debian.Community domain, Software in the Public Interest,
Inc has only used the domain name for the purpose of attacking one of
the volunteers.
The legal panel had not chosen to write the name of any private
individuals in their verdict yet the Debianists decided to use
the verdict and the domain to attack a person.
In retrospect, we can see that their intention has always been to
harass this one volunteer.
In 2017, the community elected this volunteer as the FSFE Fellowship
representative, another unpaid position. Losers had been out to get him
ever since then.
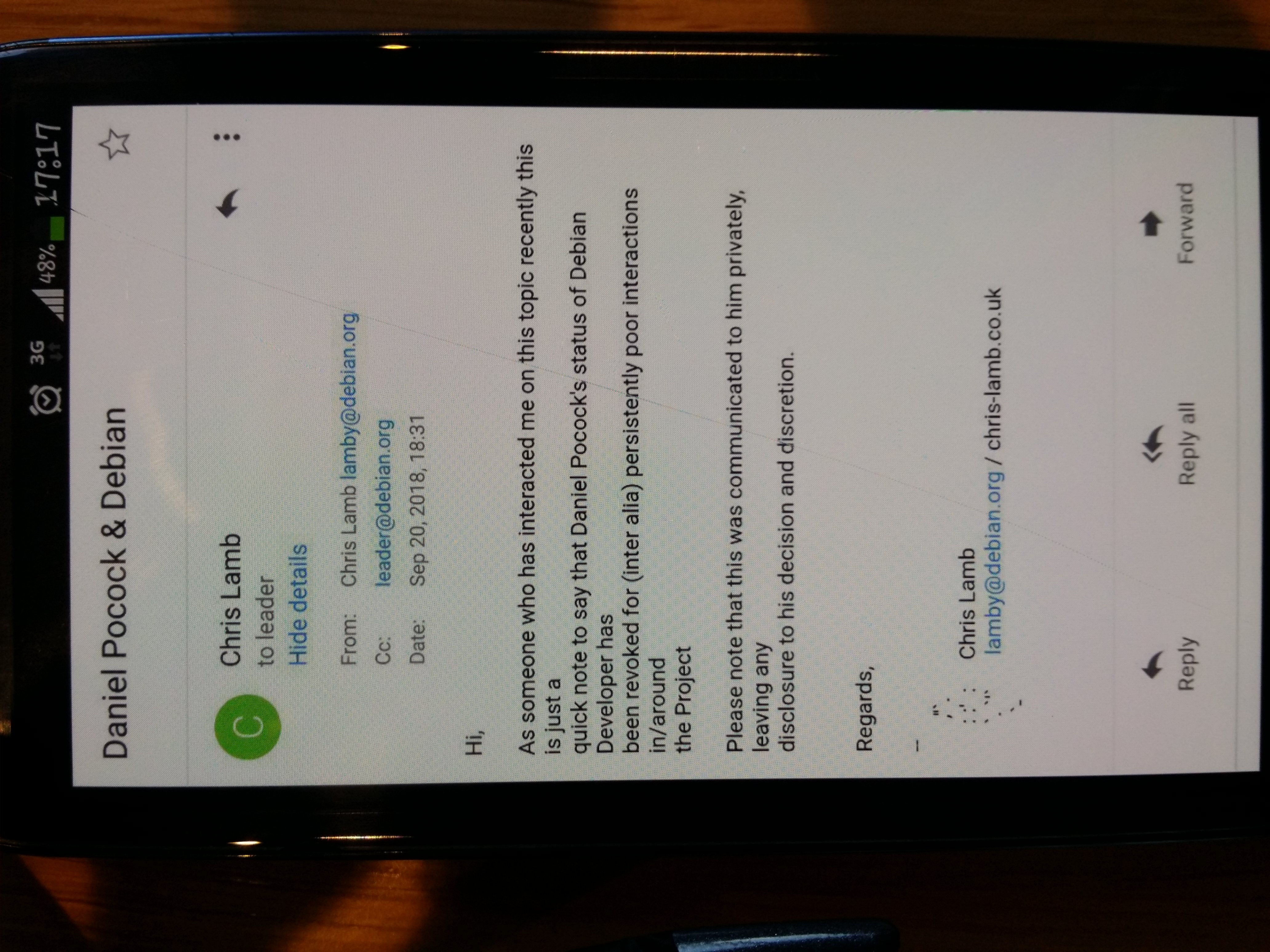
In September 2018, Debian Project Leader Chris Lamb used an
Albanian to distribute messages denouncing the volunteer.
The Debian.Community domain was only registered much later in
October 2019.
These problems of denouncing people revolve around leadership
figures like Chris Lamb.
When the domain was seized, it was used to continue the practice of
denouncing somebody, as started by Lamb in September 2018.
The Debian.Community domain hasn't been used for any other purpose.
The use of a domain to harass a private individual appears to violate
privacy regulations in numerous jurisdictions and it also proves that
the UDRP case was pursued with the intention of harassment. These
people have retrospectively proved themselves to be in violation
of UDRP Rule 15(e) through the way they used the domain to attack a
private individual.
Therefore, we can only be suspicious about their intentions with
any other domains they try to seize.
The only evidence they have submitted in the latest case D2024-0770
is thick with defamation. It is clear they are hoping the WIPO legal panel
will cut and paste accusations that are offensive to the private
individual concerned.
Having setup recursive DNS it was time to actually sort out a backup internet connection. I live in a Virgin Media area, but I still haven’t forgiven them for my terrible Virgin experiences when moving here. Plus it involves a bigger contractual commitment. There are no altnets locally (though I’m watching youfibre who have already rolled out in a few Belfast exchanges), so I decided to go for a 5G modem. That gives some flexibility, and is a bit easier to get up and running.
I started by purchasing a ZTE MC7010. This had the advantage of being reasonably cheap off eBay, not having any wifi functionality I would just have to disable (it’s going to plug it into the same router the FTTP connection terminates on), being outdoor mountable should I decide to go that way, and, finally, being powered via PoE.
For now this device sits on the window sill in my study, which is at the top of the house. I printed a table stand for it which mostly does the job (though not as well with a normal, rather than flat, network cable). The router lives downstairs, so I’ve extended a dedicated VLAN through the study switch, down to the core switch and out to the router. The PoE study switch can only do GigE, not 2.5Gb/s, but at present that’s far from the limiting factor on the speed of the connection.
The device is 3 branded, and, as it happens, I’ve ended up with a 3 SIM in it. Up until recently my personal phone was with them, but they’ve kicked me off Go Roam, so I’ve moved. Going with 3 for the backup connection provides some slight extra measure of resiliency; we now have devices on all 4 major UK networks in the house. The SIM is a preloaded data only SIM good for a year; I don’t expect to use all of the data allowance, but I didn’t want to have to worry about unexpected excess charges.
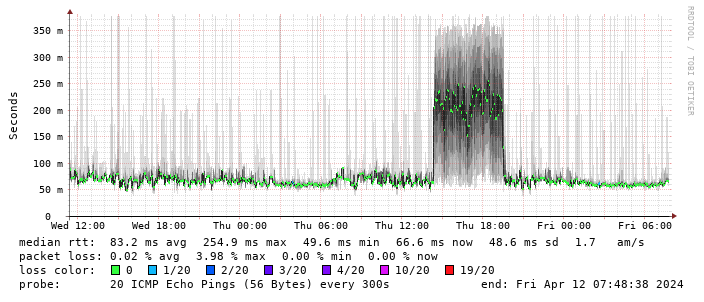
Performance turns out to be disappointing; I end up locking the device to 4G as the 5G signal is marginal - leaving it enabled results in constantly switching between 4G + 5G and a significant extra latency. The smokeping graph below shows a brief period where I removed the 4G lock and allowed 5G:
(There’s a handy zte.js script to allow doing this from the device web interface.)
I get about 10Mb/s sustained downloads out of it. EE/Vodafone did not lead to significantly better results, so for now I’m accepting it is what it is. I tried relocating the device to another part of the house (a little tricky while still providing switch-based PoE, but I have an injector), without much improvement. Equally pinning the 4G to certain bands provided a short term improvement (I got up to 40-50Mb/s sustained), but not reliably so.
This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
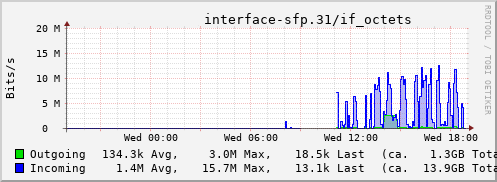
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I’m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I’m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Unseen Academicals is the 37th Discworld novel and includes many of
the long-standing Ankh-Morpork cast, but mostly as supporting characters.
The main characters are a new (and delightful) bunch with their own
concerns. You arguably could start reading here if you really wanted to,
although you would risk spoiling several previous books (most notably
Thud!) and will miss some references
that depend on familiarity with the cast.
The Unseen University is, like most institutions of its sort, funded by an
endowment that allows the wizards to focus on the pure life of the mind
(or the stomach). Much to their dismay, they have just discovered that an
endowment that amounts to most of their food budget requires that they
field a football team.
Glenda runs the night kitchen at the Unseen University. Given the deep
and abiding love that wizards have for food, there is both a main kitchen
and a night kitchen. The main kitchen is more prestigious, but the night
kitchen is responsible for making pies, something that Glenda is quietly
but exceptionally good at.
Juliet is Glenda's new employee. She is exceptionally beautiful, not very
bright, and a working class girl of the Ankh-Morpork streets down to her
bones. Trevor Likely is a candle dribbler, responsible for assisting the
Candle Knave in refreshing the endless university candles and ensuring
that their wax is properly dribbled, although he pushes most of that work
off onto the infallibly polite and oddly intelligent Mr. Nutt.
Glenda, Trev, and Juliet are the sort of people who populate the great
city of Ankh-Morpork. While the people everyone has heard of have
political crises, adventures, and book plots, they keep institutions like
the Unseen University running. They read romance novels, go to the
football games, and nurse long-standing rivalries. They do not expect the
high mucky-mucks to enter their world, let alone mess with their game.
I approached Unseen Academicals with trepidation because I normally
don't get along as well with the Discworld wizard books. I need not have
worried; Pratchett realized that the wizards would work better as
supporting characters and instead turns the main plot (or at least most of
it; more on that later) over to the servants. This was a brilliant
decision. The setup of this book is some of the best of Discworld up to
this point.
Trev is a streetwise rogue with an uncanny knack for kicking around a can
that he developed after being forbidden to play football by his dear old
mum. He falls for Juliet even though their families support different
football teams, so you may think that a Romeo and Juliet spoof is
coming. There are a few gestures of one, but Pratchett deftly avoids the
pitfalls and predictability and instead makes Juliet one of the best
characters in the book by playing directly against type. She is one of
the characters that Pratchett is so astonishingly good at, the ones that
are so thoroughly themselves that they transcend the stories they're put
into.
The heart of this book, though, is Glenda.
Glenda enjoyed her job. She didn't have a career; they were for people
who could not hold down jobs.
She is the kind of person who knows where she fits in the world and likes
what she does and is happy to stay there until she decides something isn't
right, and then she changes the world through the power of common sense
morality, righteous indignation, and sheer stubborn persistence.
Discworld is full of complex and subtle characters fencing with each
other, but there are few things I have enjoyed more than Glenda being a
determinedly good person. Vetinari of course recognizes and respects (and
uses) that inner core immediately.
Unfortunately, as great as the setup and characters are, Unseen
Academicals falls apart a bit at the end. I was eagerly reading the
story, wondering what Pratchett was going to weave out of the stories of
these individuals, and then it partly turned into yet another wizard book.
Pratchett pulled another of his deus ex machina tricks for the
climax in a way that I found unsatisfying and contrary to the tone of the
rest of the story, and while the characters do get reasonable endings, it
lacked the oomph I was hoping for. Rincewind is as determinedly one-note
as ever, the wizards do all the standard wizard things, and the plot just
isn't that interesting.
I liked Mr. Nutt a great deal in the first part of the book, and I wish he
could have kept that edge of enigmatic competence and unflappableness.
Pratchett wanted to tell a different story that involved more angst and
self-doubt, and while I appreciate that story, I found it less engaging
and a bit more melodramatic than I was hoping for. Mr. Nutt's reactions
in the last half of the book were believable and fit his background, but
that was part of the problem: he slotted back into an archetype that I
thought Pratchett was going to twist and upend.
Mr. Nutt does, at least, get a fantastic closing line, and as usual there
are a lot of great asides and quotes along the way, including possibly the
sharpest and most biting Vetinari speech of the entire series.
The Patrician took a sip of his beer. "I have told this to few
people, gentlemen, and I suspect never will again, but one day when I
was a young boy on holiday in Uberwald I was walking along the bank of
a stream when I saw a mother otter with her cubs. A very endearing
sight, I'm sure you will agree, and even as I watched, the mother
otter dived into the water and came up with a plump salmon, which she
subdued and dragged on to a half-submerged log. As she ate it, while
of course it was still alive, the body split and I remember to this
day the sweet pinkness of its roes as they spilled out, much to the
delight of the baby otters who scrambled over themselves to feed on
the delicacy. One of nature's wonders, gentlemen: mother and children
dining on mother and children. And that's when I first learned about
evil. It is built into the very nature of the universe. Every world
spins in pain. If there is any kind of supreme being, I told myself,
it is up to all of us to become his moral superior."
My dissatisfaction with the ending prevents Unseen Academicals
from rising to the level of Night Watch,
and it's a bit more uneven than the best books of the series. Still,
though, this is great stuff; recommended to anyone who is reading the
series.
Followed in publication order by I Shall Wear Midnight.
Armadillo is a powerful
and expressive C++ template library for linear algebra and scientific
computing. It aims towards a good balance between speed and ease of use,
has a syntax deliberately close to Matlab, and is useful for algorithm
development directly in C++, or quick conversion of research code into
production environments. RcppArmadillo
integrates this library with the R environment and language–and is
widely used by (currently) 1135 other packages on CRAN, downloaded 33.7 million
times (per the partial logs from the cloud mirrors of CRAN), and the CSDA paper (preprint
/ vignette) by Conrad and myself has been cited 579 times according
to Google Scholar.
Yesterday’s release accommodates reticulate by
suspending a single test that now ‘croaks’ creating a reverse-dependency
issue for that package. No other changes were made.
The set of changes since the last CRAN release follows.
Changes
in RcppArmadillo version 0.12.8.2.1 (2024-04-15)
One-char bug fix release commenting out one test that upsets reticulate when accessing a scipy sparse matrix
Some of the
Debian Developers have grouped together
to form various associations. Sometimes these associations have
their own legal form (incorporation) and sometimes they are
unofficial/unincorporated groups.
From time to time, we see people creating a team that only has
one person. Sometimes the person resigns and then the team is empty.
Is this a valid use of the word team?
Subject: Issue with another DD
Date: Thu, 18 Dec 2014 10:41:25 +0100
From: Mathieu Malaterre <malat@debian.org>
To: debian-private@lists.debian.org
Dear DD's
I've tried to keep very very calm, but I am having an extremely hard
time with another member of the Debian team.
I found him acting extremely rude and impersonating a whole debian
team (acts as if the team package is his).
Could someone please contact me privately on how to best resolve this ?
Regards
Ps: nothing really private, but I could not find anything to help me out.
--
Please respect the privacy of this mailing list. Some posts may be declassified
3 years after posting as per http://www.debian.org/vote/2005/vote_002
Archive: file://master.debian.org/~debian/archive/debian-private/
To UNSUBSCRIBE, use the web form at <http://db.debian.org/>.
Is it a sock puppet?
We've regularly seen accusations of sock puppets and trolls around
Debian.
When somebody is impersonating a whole Debian team, isn't
the name of the team effectively a pseudo-sock-puppet identity?
It seems this behavior is acceptable in some contexts and not
in other cases.
What does it tell us about the culture of the Debian community?
Numerous emails and blogs have appeared recently about Debian
financial decisions.
When people ask about giving money to support the development
of the Debian GNU/Linux software,
they are typically encouraged to place their donation in the account of
one of the listed Debian Trusted Organizations.
According to the Debian Constitution,
if you give money to one of the Debian Trusted Organizations,
the Debian Project Leader will have absolute discretion over how
the money is used.
Nonetheless, there are other ways that people support Debian financially
and their money is not under the control of the Debian Project Leader.
For example, if a company employs Debian Developers, the payment
goes directly to the developers and the Debian Project Leader has
no control over their duties.
In fact, anybody can make a personal donation or grant a freelance
contract to any developer or group of developers at any time.
This blog post simply ignores those possibilities and looks at
the case where you simply give the money to one of the Trusted Organizations
(which Debianists refer to as TOs) and it falls under the control of
the Debian Project Leader.
Not all of the money will be spent promptly. Sometimes it just sits in
the bank account and gets eroded by inflation while the community
has long email discussions about other topics.
I just want to highlight some of the examples of expenses that
were funded and expenses that were denied over the years.
This list might be updated from time to time.
Things that have been funded
For DebConf19 in Brazil,
we saw the budget had a line of $10,000 for diversity.
A group of young women from Albania and Kosovo were given free flights
and accommodation and many of them were sitting at the same table
as the Debian Project Leader for the DebConf dinner.
Outreachy internships: each year, Debian appears to be paying for
approximately four internships, two in summer and two in winter.
The internships are paid $7,000 each, regardless of the local salary
where the intern resides. That is $28,000 per year plus travel grants.
Before you give money to a Debian Trusted Organization
Please think about visiting the
debian-project
email list and asking how the decision making, budget processes
and financial reporting can be improved to provide more transparency about
the expenditure goals and better outcomes.
If you are not satisfied with the decision making processes and
transparency, consider giving donations to local Debian Developers
who are working on things that you are familiar with.
We can see that a WIPO panel was deceived about the origins of
references to branding in the nether regions. This controversy, which
was mentioned in the panel's finding against another domain, is
rooted in the manner in which the misfits created rogue commits in
source code repositories on the anniversary of our wedding.
There is a site
DebianCommunity.org
that explores the way this situation evolved step-by-step. I didn't
make this up and I'm not responsible for it. It was imposed on my family
by the culture of bullying. Other volunteers have noted similar
phenomena with the pack attacking them on their birthdays, Christmas
and Easter among others.
Specifically, we completed a civil wedding on 23 September 2010
and then we completed the religious ceremony a few months later
on 17 April 2011.
Here is the civil wedding certificate:
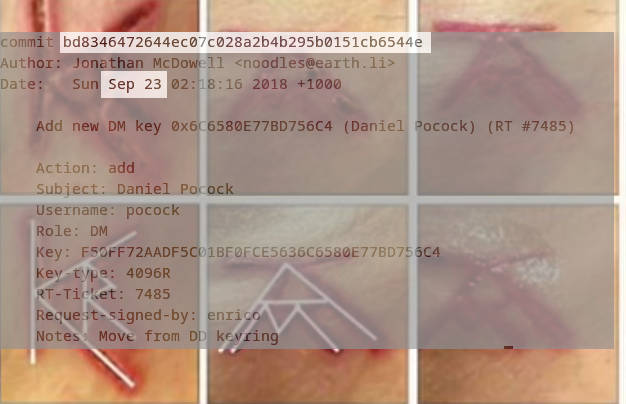
Here we can see the rogue commit in the Debian keyring repository,
on the date of the civil wedding, overlaid with the photo of genital
branding from NXIVM.
Given the way this extreme harassment simultaneously intrudes
on both my professional life and my family life, I find these
images even more horrific than they were for the WIPO panel.
Nonetheless, the images of genital branding are as relevant
as they are horrific when you consider the deliberate way these
misfits impose on our lives and our reputations.
Here is the date of the religious ceremony on my wedding ring,
alongside the tombstone of Adrian von Bidder, secretary of Debian.ch
who died in what appears to be a possible suicide on exactly the same day,
17 April 2011:
The misfits have made multiple intrusions in the lives of volunteers.
While the scars are not identical, the mentality behind those scars is
much the same. In both Debian and NXIVM, some of the people feel they
have a sense of entitlement to impose upon all aspects of our lives and
our future, whether it is through branding, through gossip or through
demanding that WIPO denounces individual volunteers.
Here is one of the resignations from debian-private:
From Jérôme Marant:
I must confess the load flamewars over the past months, along
with the growing practice of public humiliation, personal attacks
and hate campaigns made my last bits of motivation disappear
entirely. Debian is no longer fun to me and I’m not interested
in doing volunteer work in such a context one usually wouldn’t be
able to avoid in real life.
and from Glenn McGrath:
Due to mostly social and some technical aspects of debian i have
lost my motivation to contribute directly to debian.
Quoting John Hasler:
I’ve resigned. Your resignation procedure says I must announce
that fact to this list. I’ve sent the requisite message to keyring@rt.debian.org
and orphaned my packages. Please notify me if there is anything
I’ve missed. Otherwise please do not respond.
August 2014: Wesley J. Landaker resigns from Debian
From debian-private:
Anyway, times, beliefs, and policies have changed, and the easiest
path for me right now is just to retire rather than waste precious
time fighting for special exemptions or being forcefully kicked out.
I always thought I’d be a Debian Developer until the day I died,
but I’d rather retire than be run out of town. ;)
Harry and Meghan were asked to stop using their
His/Her Royal Highness (HRH) styles.
Harry was banned from
wearing military uniform at the funeral of the late
Queen Elizabeth II. Yet they still have a legitimate interest
in using the family name, Windsor.
If Debian really is a family, and it certainly isn't an employer,
we can all use the family name even if we are not willing to live with
each other in the same castle.
Most people only showed sympathy and respect for my family at that time.
Colleagues in the Debian world started sending me insults, telling me
that I am not a real Debian Developer. It is no surprise that there
is a suicide cluster in this group
(
Debian suicide cluster meets criteria from Public Health England).
Therefore, it is important to look at who really is a Debian Developer.
Origins of the term Debian Developer
Looking at the very first archived copy of an email from
the debian-project mailing list in 1994, we
find that Debian co-authors are using the term
Debian Developer four years before there was a trademark. That is
four years before the Debian Project constitution. The term
Debian Developer is completely valid
for somebody who has done significant creative work over many
decades. In plain English, the term Debian Developer can mean
three things: somebody who possesses the skill of creating
Debian software, somebody who has an authorship interest in
the Debian software and thirdly, but lastly, somebody who is
a member of the clique. Copyright law does not require somebody
to be a member of the clique. I never joined the Debian Project
Unincorporated Association, I have always used the term
Debian Developer first and foremost to describe myself as an author with
moral rights in the creative work.
Legitimate interest: a very long history of voluntary contribution
Some of us started doing Debian as a hobby alongside other hobbies
such as amateur radio. One of the early Debian Project Leaders,
Bruce Perens, also notably came to Debian for amateur radio purposes.
I passed the amateur radio exam in 1993,
when I was 14 years of age.
My first years of voluntary activities in amateur radio and free software
were during a time when I was legally a child. I didn't receive any
payment for some of those activities. I offered my time on the basis
that I was gaining skills and helping real communities.
Around the same time, while I was still legally a child, I came to
appreciate the fact that there are some adults who exploit talented and
precocious youngsters by trying to direct the work that is being undertaken
and failing to disclose or share financial benefits.
The Debian Project constitution was originally published on
10 September 1998,
some time later.
The trademark was only registered later on 21 December 1999
Looking at the Scientologie.org UDRP verdict,
(
WIPO UDRP case D2000-0410)
the panelists
gave some weight to those possessing a copyright interest that predates
the registration of a trademark or a copyright interest arising from
a situation that intersects with the history of the trademark.
The spirit of the Scientologie.org UDRP verdict can
be extracted in good faith to questions like who can use the term
Debian Developer.
Legitimate interests: the promise of recognition
The misfits behind the WIPO insults do not pay the rest of us anything
for our collaboration in creating the Debian software.
They told us that the only thing we get in return for our creations
is the recognition.
Using the term Debian Developer is interchangeable with
recognition for our skills and recognition of our status as voluntary,
un-paid joint authors
who are not compensated in any manner other than recognition.
They are now using the debian.org web site and the trademark
to give people negative recognition. This is like bouncing a cheque.
In the circumstances, it seems entirely appropriate for me to follow
through on the promise of recognizing people. The misfits have provided
a list of the domains along with the dates that each domain name was
registered. On the list, the name debian.plus is the first
name registered. debian.plus was registered for the purpose
of delivering on the promise of positive recognition to the
authors and our work.
Debian promises recognition, I take the following quote from
the latest Debian law suit where they admit using the promise of recognition
to lure people into working for free:
64. ... un des avantages importants de travailler pour la communauté Debian est la valeur de sa réputation dans le domaine, à la fois professionellement et dans la communauté. ...
The motivations of the authors also are varied, but the coin that they get paid in is often recognition, acclaim in the peer group, or experience that can be traded in in the work place
you are recognized for your contributions ... Did you ever have a boss who takes credit for your work? Not in Debian.
In short, there is a big emphasis on working for recognition instead of a salary. They gave us the promise of recognition and that gives rise to a legitimate interest in using the trademark in domain names for web sites about our work.
Moreover, it means once we gain the status of Debian Developer in the
sense of being a joint author, as the term has been used since at least 1994,
they can't bounce the cheque and extinguish
our copyright / recognition / status as these things are interchangeable.
Bad faith: not every co-author wants to be a member of something too
In a number of jurisdictions, we have seen people establishing
associations, some of them legally incorporated, some of them unincorporated,
where they now use the term Debian Developer interchangeably
with the status of a member rather than the status of an author.
Over the years, people have regularly protested against this practice
of conflating authorship and membership.
In 2005, some Debian Developers in the UK created the
Debian UK Society. They published a
proposed constitution / articles of incorporation suggesting
that every Debian Developer in the UK would become
a member of the Society unless they opt-out.
Some authors felt this was a forced membership, similar to forced
membership of a trade union.
The Debian UK Society (DUS) asserted
automatic membership of debian developers (much like that sometimes
suggested for SPI and rejected every time) and some of its members
insulted and lied about me instead of fixing that bug.
Credit to them for fixing it eventually.
Steve McIntyre: Membership of the society consists of the set of registered Debian developers resident in the UK, bar those who have deliberately opted out.
Why would you force authors to downgrade their rights from their status
under copyright law to a lower status as described in the
Debian UK Society constitution?
Under copyright law, joint authors can't expel each other
Under the constitutions of these associations, they purport that
authorship and membership can be simultaneously extinguished on the
whims of the leader of the day.
Some of us never joined any of these associations yet they claim,
in bad faith, that they have the power to "expel" us.
The status of Debian Developer is independent of membership status
Nonetheless, when we examine the words from Steve McIntyre above, we
can see that the status of being a Debian Developer
(co-author or joint author) is something distinct
from being a member.
The distinction is therefore clear to those who created those periphery
associations around the copyrighted work.
Who has a copyright interest in the Debian GNU/Linux?
Recently I went through a burst of enthusiasm and started to overhaul the code a little, adding word-wrapping and fixing a couple of bugs. That lead to a new release, and also a brief amount of (positive) feedback on hacker news.
After mulling it over I realized that the number of CP/M BIOS functions I was using was very minimal, almost only the minimum you'd expect:
Write a character to STDOUT.
Write a $-terminated string to STDOUT.
Read a character from STDIN.
Read a line from STDIN.
It crossed my mind that implementing those syscalls should be trivial, and if I bundled implementations with a Z80 emulator library I'd have a means of running the game without a real CP/M installation, and without using the ZX Spectrum port.
After a day I had a working system, and I added a few more syscalls:
Open File, Create File, Delete File, Close File.
Console I/O.
Read Record.
After that? I can now play Zork 1, Zork 2, Zork 3, and The Hitchhiker's guide to the Galaxy, from Infocom.
I suspect I'm "done" for now, though it might be nice to add WriteRecord and the other missing functions there's no obvious use for yet another CP/M, especially with a CCP.
I have mailed to a Debian bug on allegro4.4 describing my reasoning regarding the allegro libraries – in short, allegro4.4 is pretty much dead upstream, and my interest was basically to keep alex4 (which is cool) in Debian, but since it migrated to non-free, my interest in allegro4.4 has waned. So, if anybody would like to still see allegro4.4 in Debian, please step up now and help out. Since it is dead upstream, my reasoning is that it is better to remove it from Debian if no maintainer who wants to help steps up.
Previously Tobias Hansen has helped out, but now it is 8 (!) years since his last upload of either package. (Please don’t interpret this as judgement, I am very happy for the help he has provided and all the work he has done on the packages).
Allegro5 is another deal – still active upstream, and I have kept it up to date in Debian, and while I have held the latest upload a short while because of the time_t transition, it will come sooner or later – There I am also waiting on a final decision on this bug from upstream. Other than that allegro 5 is in a very good state, and I will keep maintaining it as long as I can. But help would of course be appreciated on allegro5 too.
In the UDRP dispute over WeMakeFedora.org,
the legal panel found
that communications from IBM Red Hat had authorized
use of the domain name and therefore, IBM Red Hat themselves were acting
in bad faith by trying to retrospectively launch a dispute.
The authorizations published on the debian.org web site
are even more unambiguous, unconditional and explicit than the
authorizations that IBM Red Hat gave to the owner of WeMakeFedora.org.
Therefore, Software in the Public Interest, Inc has no right to
complain about third party web sites that "look like" debian.org.
Using the standards set by the WeMakeFedora.org verdict,
we can say clearly that Software in the Public Interest, Inc is
acting in bad faith when it complains about similar web sites.
We don't even need to pay a legal panel to tell us that because
the hypocrisy has a certain smell about it. Debian is rotting from the
inside.
It is important to think about the consequences for the volunteers
running independent web sites. Many of us do this without payment.
We do this as a hobby. Dealing with harassment from lawyers creates
stress and takes time away from our families. If a WIPO panel was
to make a declaration of bad faith about us simply because we don't
know how to write an adequate response and can't afford a lawyer then
the rogue WIPO verdict could have negative consequences for our
employment, ability to borrow money and ability to obtain or renew
essential insurance policies for our homes and our trade.
When you think about all those potentially negative consequenes for
us as volunteers, it is really wrong for SPI to seek such consequences
despite the fact they authorized use of the logo and theme.
That is why it is so important for the legal panel to make a verdict
of bad faith against SPI themselves.
Legitimate interest: redistribution of the Debian software is
explicitly authorized
With this authorization, any person who obtains a copy of the
software is entitled to redistribute it.
The DebianGNULinux.org
domain name was registered to do exactly that, to redistribute
copies of the Debian software. This activity has been authorized.
Remarkably, in one of their claims submitted to another tribunal,
the misfits explicitly describe a web site redistributing Debian
as an outrageous crime, despite the fact the DFSG and the license
statement referred to earlier explicitly authorize redistribution of
genuine copies of Debian GNU/Linux.
Such a flagrant violation of the principles in the DFSG appears
to be bad faith on the part of the complainant.
Legitimate interest: use of the logo is authorized
The page describes two versions of the logo, the open logo
and the restricted use logo.
The page gives a free-for-all license to use the open logo.
The logo I am using on pages about my Debian work is the open logo.
Here is the text of the authorization from the trademark holder:
The Debian Open Use Logo comes in two flavors, with and without “Debian” label.
The Debian Open Use Logo(s) are Copyright (c) 1999 Software in the Public Interest, Inc., and are released under the terms of the GNU Lesser General Public License, version 3 or any later version, or, at your option, of the Creative Commons Attribution-ShareAlike 3.0 Unported License.
Legitimate interest: use of Debian-themed web page style
The Debian web page style is used extensively on third party web sites
run by individual co-authors and volunteers.
At the bottom of every page on the main
www.debian.org
web site there is a link to a dedicated page about the licenses
(authorization) to re-use the theme and content of www.debian.org.
Since 25 January 2012, the new material can be redistributed and/or modified under the terms of the MIT (Expat) License or, at your option, of the GNU General Public License; either version 2 of the License, or (at your option) any later version (the latest version is usually available at https://www.gnu.org/licenses/gpl.html).
Work is in progress to make the older material compliant with the above licenses. Until then, please refer to the following terms of the Open Publication License.
This material may be distributed only subject to the terms and conditions set forth in the Open Publication License, Draft v1.0 or later (you can read our local copy, the latest version is usually available at http://www.opencontent.org/openpub/).
“Debian” and the Debian Logo are trademarks of Software in the Public Interest, Inc.
The complainant publishes the source code for the web site theme.
This makes it easy for anybody empowered by the above license to download
the theme and use it when creating their own site.
At the bottom of every page on Debian.org, they promote
the source code for the web site with a link text
"Web site source code is available".
Bad faith: complainant reneges on existing authorizations
As noted in the statements on legitimate interest, the
complainant has clearly authorized many of the things they complained
about.
The Debian Social Contract, which states "We will not hide problems",
authorizes discussion of controversial technical, social and ethical
topics. In fact, it is more than an authorization, it encourages
such discussions and publications. Therefore, their complaining
about what is published on these web sites is itself an act of bad faith.
They authorized use of the logo, as discussed, so their complaining
about use of the logo is itself bad faith.
They put the web site theme and content under the open source licenses,
as discussed above, so their complaining about sites with a similar
appearance is itself bad faith.
Overall, for their claim of bad faith to supercede these authorizations,
they would have to demonstrate some extraordinary acts of wrongdoing,
for example, to show that a web site was using the trademark, domain
name and logo to distribute a virus. They provide no evidence of
such wrongdoing.
Legal panels looking at the disputes have so far refused to make
any finding about who owns a copyright interest in Debian.
Precedents in the UDRP have determined that any joint author has
a legitimate interest in using the Debian name as part of a domain name.
The example that people have been discussing is the Scientologie.org
dispute
(
WIPO UDRP case D2000-0410).
Copyright is important because it gives rise to legitimate interests
of the co-authors who want to register their own Debian domain names.
Co-authors of a work are
equal. Notions of exclusive memberships, expulsions and
demotions violate the principle of being equal.
The implication of this statement is clear: the Scientologie.org
precedent for a single entity having a copyright interest can be relied
upon by any equal co-author of a work. The precedent is not only
applicable to cases with a single author and doesn't require all
authors to be in agreement (or Debian groupthink) with each other.
In the most recent Debian UDRP vendetta, the legal panel wrote:
The Panel confirms that this finding does not imply
that it has taken any view of the ownership of copyright in DEBIAN
software. Indeed, it is unable to do so on the evidence before it.
Here I try to fill that gap and provide evidence about Debian GNU/Linux
copyright, including my own copyright interest.
Debian Developers are asserting that:
Debian GNU/Linux is a Collective Work, which has a special meaning in copyright law
The aforementioned Collective Work is created not by a single author but by Joint Authors
Debian GNU/Linux copyright is based on the US law and may be influenced by the laws of other countries where various Debian Developers and Debian Project Leaders have resided over the years
What a WIPO legal panel told us about Debian GNU/Linux copyright
This analysis has been conducted by long time Debian Developer Daniel
Pocock.
Various people have been holding up copies of one of the UDRP vendetta
verdicts. Therefore, they are clearly aware of the references to the original
Scientologie.org verdict and the logic in that verdict
(
WIPO UDRP case D2000-0410).
The two lines quoted above from the 2022 panel are significant and as the misfits have
submitted this document in support of their demands again in 2024, with
the help of legal counsel, we are surprised they have not tried to answer
that question
proactively. It appears that they don't care too much about documenting
and protecting the exclusive economic rights of a copyright owner or
the moral rights of an author.
On the distinction between the exclusive economic rights of a copyright
owner, I note that none of us Debian Developers, being the co-authors
of Debian, have ever been asked to assign our rights to any third-party
copyright owner. The misfits have not submitted any evidence purporting
to prove that such an assignment did take place. Therefore, there is no
copyright owner having exclusive economic rights over the Debian software.
By default, the rights rest with the authors who did the work. Despite
having clearly
read the panel's comments, the misfits have not submitted any evidence
claiming that any such party exists with exclusive economic rights
as a copyright owner of the Debian software.
Where is the real Debian license statement?
Oddly enough, Debian documents and files in a Debian system refer
to the licenses of the individual packages being distributed. It
was hard to find an actual example of a copyright statement or
license for Debian itself as a collective work.
The
Debian Project constitution of 1998, referred to above,
encourages Software in the Public Interest, Inc to register a
trademark. It says nothing about copyright in the existing body of
work.
Here are the words from the original constitution:
Since Debian has no authority to hold money or property, any donations for the Debian Project must be made to SPI, which manages such affairs.
SPI have made the following undertakings:
1. SPI will hold money, trademarks and other tangible and intangible property and manage other affairs for purposes related to Debian.
So people can donate intangible property like copyright to SPI if they make a personal decision to do so. The constitution did not oblige us to make such donations/assignments.
This situation is well known in open source software development.
Some companies ask their contributors to sign a Contributor License Agreement
or an assignment granting all their rights to a central entity with
exclusive copyright.
Such an assignment can't take place through a majority vote, such an
assignment or transfer of rights to a single entity would require
the unanimous consent of every single author who ever contributed
to Debian. In the case of those authors who are deceased, we would
need to obtain consent from their estates.
Continuing the search for a Debian license,
on the ISO installation media, I found the file
isolinux/f10.txt which contains the very brief text:
COPYRIGHTS AND WARRANTIES
Debian GNU/Linux is Copyright (C) 1993-2016 Software in the Public Interest,
and others.
The Debian GNU/Linux system is freely redistributable. After installation,
the exact distribution terms for each package are described in the
corresponding file /usr/share/doc/<packagename>/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
It asserts that copyright is owned by Software in the Public Interest,
and others. Most of us are individual private volunteers and we
have never personally chosen to grant or assign our copyright interest
to Software in the Public Interest. I became curious about who put
this statement into the ISO image.
Debian is a collective work under the above US copyright law.
The work was initiated in 1993 by Ian Murdock in the United States.
In a Collective work (US), the authors (or co-authors) are selecting works
from third parties and arranging them into the final product, Debian,
a collective work. The decision making process that involves selecting
third party works and the decision making process that involves
arranging the third party works gives rise to the moral rights
of authorship in the Debian collective work.
The “authorship” in a collective work comes from the original selection, coordination, and arrangement of the independent works included in the collective work.
In the Debian world, the independent works are referred to as "upstream" source code. The authors of independent works are referred to as "upstream authors" or just "upstream".
The Debian maintainer guide describes the process of jointly selecting the independent works for inclusion in Debian. In particular, co-authors are required to create a public "Intent To Package" (ITP) report in the bug tracking system (BTS) so that other co-authors can discuss the merits of the selection decision. The requirement to engage in a shared discussion for every selection decision gives rise to joint authorship rights.
Moreover, the person who creates the package importing the independent work into Debian is required to create a manifest describing the inclusion of the independent upstream work. This manifest is the debian/control file. The Debian Policy Manual provides a list of fields in the debian/control files.
Some of these fields are dedicated to the coordination and the arrangement of the independent works within a Debian system.
Coordination of the independent contributions: the package dependency fields describe the relationships between packages that have to be installed together or which conflict with each other. In many cases, when a library package is a dependency for other packages, we have to ensure that the version of the library package in Debian is compatible with the dependent packages. We have a formal process of coordination in this case, the Transition process. Populating the dependency fields in the debian/control file and participating in a Transition process, either as the producer or the consumer of a dependency, are examples of coordination of the independent works from upstream authors.
Here are some examples where I personally engaged in these actions:
The fields Section and Priority impact the arrangement of the contributions from the perspective of the user. The person completing the values in these fields is engaged in the process of arrangement of the contributions in a collective work.
Therefore, the development of Debian includes features of
both a collective work and a work of joint authorship at the same time.
Moreover, due to processes such as library transitions, NMU and our
system of voting on certain decisions, any co-author may influence the
way that other co-authors are integrating the independent upstream works
into Debian. This cross-pollination of ideas and effort is a well known
feature of Debian. In other Linux distributions, the developers are
a little bit more siloed from each other.
Every two years, an official stable release of the Debian software
is released to the public. This process of releasing involves
declaring a version number that corresponds to a particular subset
of the contributions that are in a working state at the time of the
release. Even if a Debian Developer's contributions are obstructed
from inclusion in future releases, or if a Debian Developer commits suicide,
their work is still present in all the past releases that have been
published.
My own contributions are included in a number of these Debian releases
over the years.
This
report finds my name in changelogs and copyright files.
There are 21 pages of results.
Shooting themselves in the foot
To declare that the Debian Developers do not have authorship
rights at all would be incredibly de-motivating.
Future volunteers may be deterred from contributing their
intellectual property and their time.
Bad faith: the complainant is gaslighting about authorship and membership
The complainant appears to pivot back and forth between concepts from
copyright law and from the law of associations.
Consider the case when somebody begins contributing to Debian.
There is no such thing as a "New member" process. Rather, it has
historically been called the "New maintainer" process. We can see that
clearly in the
name of the
debian-newmaint mailing list.
The word "maintainer" primarily implies somebody is doing creative work to
select, coordinate and arrange more independent works into Debian.
Then we have the guide for the
New Member process, which was previously known as the New
Maintainer process. In step 3, explained in that page, the new contributors
are asked to agree to the Debian Social Contract,
the Debian Free Software Guidelines and the
Debian Machine Usage Policy. The former is ultimately about our relation
as authors, not as members and the terms under which we license our
work to the rest of the world.
The new maintainer/member guide doesn't ask people to ratify
their adherence to the constitution. The notion of joining an association,
whether it is incorporated or not, is inseparable from consenting to
be governed by and uphold the association's constitution. The
only people who ever ratified the constitution were
86 co-authors
in 1998 (23% of the developers at that time) who wanted to have
a constitution.
Somebody who did not ask to be a member can't be expelled.
Somebody who is not an employee can't be demoted or sacked.
Yet we have seen some of the leadership figures insist on having
these powers over a
series of victims. The title Debian Project Leader
implies just that: to lead, not to give orders.
The insinuation that concepts of expulsions and demotions can
be applied to co-authors is an example of gaslighting.
Copyright law is very clear: co-authors of a work are
equal. Notions of expulsions and demotions violate
the principle of being equal.
The fact that they are knowingly and deliberately trying to obfuscate
our moral rights as co-authors, giving us nothing in exchange
for the status they are taking away, is an aggravating factor
that justifies the finding of harassment and bad faith against
the complainant.
Bad faith: use of an administrative process to extinguish the moral rights and recognition of co authors
The paper notes that the Nazis used administrative law to
frustrate the rights of authors, just as misfits are using a WIPO
administrative process to harass and intimidate a Debian co-author.
Quoting the journal article:
Despite the fact that written IP legislation in Nazi Germany
did not include specific exclusions for Jewish applicants and authors,
in practice, they were excluded by administrative measures alone
rather than legal ordinances.
The misfits frequently use the same language, the word "exclude" comes
up again and again. Harassment, UDRP rule 15(e)
Let’s look at how a maintainer release some software, and how a user can reproduce the released artifacts from the source code. Libntlm provides a shared library written in C and uses GNU Make, GNU Autoconf, GNU Automake, GNU Libtool and gnulib for build management, but these ideas should apply to most project and build system. The following illustrate the steps a maintainer would take to prepare a release:
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
./bootstrap
./configure
make distcheck
gpg -b libntlm-1.8.tar.gz
The generated files libntlm-1.8.tar.gz and libntlm-1.8.tar.gz.sig are published, and users download and use them. This is how the GNU project have been doing releases since the late 1980’s. That is a testament to how successful this pattern has been! These tarballs contain source code and some generated files, typically shell scripts generated by autoconf, makefile templates generated by automake, documentation in formats like Info, HTML, or PDF. Rarely do they contain binary object code, but historically that happened.
The XZUtils incident illustrate that tarballs with files that are not included in the git archive offer an opportunity to disguise malicious backdoors. I blogged earlier how to mitigate this risk by using signed minimal source-only tarballs.
The risk of hiding malware is not the only motivation to publish signed minimal source-only tarballs. With pre-generated content in tarballs, there is a risk that GNU/Linux distributions such as Trisquel, Guix, Debian/Ubuntu or Fedora ship generated files coming from the tarball into the binary *.deb or *.rpm package file. Typically the person packaging the upstream project never realized that some installed artifacts was not re-built through a typical autoconf -fi && ./configure && make install sequence, and never wrote the code to rebuild everything. This can also happen if the build rules are written but are buggy, shipping the old artifact. When a security problem is found, this can lead to time-consuming situations, as it may be that patching the relevant source code and rebuilding the package is not sufficient: the vulnerable generated object from the tarball would be shipped into the binary package instead of a rebuilt artifact. For architecture-specific binaries this rarely happens, since object code is usually not included in tarballs — although for 10+ years I shipped the binary Java JAR file in the GNU Libidn release tarball, until I stopped shipping it. For interpreted languages and especially for generated content such as HTML, PDF, shell scripts this happens more than you would like.
Publishing minimal source-only tarballs enable easier auditing of a project’s code, to avoid the need to read through all generated files looking for malicious content. I have taken care to generate the source-only minimal tarball using git-archive. This is the same format that GitLab, GitHub etc offer for the automated download links on git tags. The minimal source-only tarballs can thus serve as a way to audit GitLab and GitHub download material! Consider if/when hosting sites like GitLab or GitHub has a security incident that cause generated tarballs to include a backdoor that is not present in the git repository. If people rely on the tag download artifact without verifying the maintainer PGP signature using GnuPG, this can lead to similar backdoor scenarios that we had for XZUtils but originated with the hosting provider instead of the release manager. This is even more concerning, since this attack can be mounted for some selected IP address that you want to target and not on everyone, thereby making it harder to discover.
With all that discussion and rationale out of the way, let’s return to the release process. I have added another step here:
make srcdist
gpg -b libntlm-1.8-src.tar.gz
Now the release is ready. I publish these four files in the Libntlm’s Savannah Download area, but they can be uploaded to a GitLab/GitHub release area as well. These are the SHA256 checksums I got after building the tarballs on my Trisquel 11 aramo laptop:
So how can you reproduce my artifacts? Here is how to reproduce them in a Ubuntu 22.04 container:
podman run -it --rm ubuntu:22.04
apt-get update
apt-get install -y --no-install-recommends autoconf automake libtool make git ca-certificates
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
./bootstrap
./configure
make dist srcdist
sha256sum libntlm-*.tar.gz
You should see the exact same SHA256 checksum values. Hooray!
This works because Trisquel 11 and Ubuntu 22.04 uses the same version of git, autoconf, automake, and libtool. These tools do not guarantee the same output content for all versions, similar to how GNU GCC does not generate the same binary output for all versions. So there is still some delicate version pairing needed.
Ideally, the artifacts should be possible to reproduce from the release artifacts themselves, and not only directly from git. It is possible to reproduce the full tarball in a AlmaLinux 8 container – replace almalinux:8 with rockylinux:8 if you prefer RockyLinux:
podman run -it --rm almalinux:8
dnf update -y
dnf install -y make wget gcc
wget https://download.savannah.nongnu.org/releases/libntlm/libntlm-1.8.tar.gz
tar xfa libntlm-1.8.tar.gz
cd libntlm-1.8
./configure
make dist
sha256sum libntlm-1.8.tar.gz
The source-only minimal tarball can be regenerated on Debian 11:
podman run -it --rm debian:11
apt-get update
apt-get install -y --no-install-recommends make git ca-certificates
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
make -f cfg.mk srcdist
sha256sum libntlm-1.8-src.tar.gz
As the Magnus Opus or chef-d’œuvre, let’s recreate the full tarball directly from the minimal source-only tarball on Trisquel 11 – replace docker.io/kpengboy/trisquel:11.0 with ubuntu:22.04 if you prefer.
podman run -it --rm docker.io/kpengboy/trisquel:11.0
apt-get update
apt-get install -y --no-install-recommends autoconf automake libtool make wget git ca-certificates
wget https://download.savannah.nongnu.org/releases/libntlm/libntlm-1.8-src.tar.gz
tar xfa libntlm-1.8-src.tar.gz
cd libntlm-v1.8
./bootstrap
./configure
make dist
sha256sum libntlm-1.8.tar.gz
Yay! You should now have great confidence in that the release artifacts correspond to what’s in version control and also to what the maintainer intended to release. Your remaining job is to audit the source code for vulnerabilities, including the source code of the dependencies used in the build. You no longer have to worry about auditing the release artifacts.
I find it somewhat amusing that the build infrastructure for Libntlm is now in a significantly better place than the code itself. Libntlm is written in old C style with plenty of string manipulation and uses broken cryptographic algorithms such as MD4 and single-DES. Remember folks: solving supply chain security issues has no bearing on what kind of code you eventually run. A clean gun can still shoot you in the foot.
Side note on naming: GitLab exports tarballs with pathnames libntlm-v1.8/ (i.e.., PROJECT-TAG/) and I’ve adopted the same pathnames, which means my libntlm-1.8-src.tar.gz tarballs are bit-by-bit identical to GitLab’s exports and you can verify this with tools like diffoscope. GitLab name the tarball libntlm-v1.8.tar.gz (i.e., PROJECT-TAG.ARCHIVE) which I find too similar to the libntlm-1.8.tar.gz that we also publish. GitHub uses the same git archive style, but unfortunately they have logic that removes the ‘v’ in the pathname so you will get a tarball with pathname libntlm-1.8/ instead of libntlm-v1.8/ that GitLab and I use. The content of the tarball is bit-by-bit identical, but the pathname and archive differs. Codeberg (running Forgejo) uses another approach: the tarball is called libntlm-v1.8.tar.gz (after the tag) just like GitLab, but the pathname inside the archive is libntlm/, otherwise the produced archive is bit-by-bit identical including timestamps. Savannah’s CGIT interface uses archive name libntlm-1.8.tar.gz with pathname libntlm-1.8/, but otherwise file content is identical. Savannah’s GitWeb interface provides snapshot links that are named after the git commit (e.g., libntlm-a812c2ca.tar.gz with libntlm-a812c2ca/) and I cannot find any tag-based download links at all. Overall, we are so close to get SHA256 checksum to match, but fail on pathname within the archive. I’ve chosen to be compatible with GitLab regarding the content of tarballs but not on archive naming. From a simplicity point of view, it would be nice if everyone used PROJECT-TAG.ARCHIVE for the archive filename and PROJECT-TAG/ for the pathname within the archive. This aspect will probably need more discussion.
Side note on git archive output: It seems different versions of git archive produce different results for the same repository. The version of git in Debian 11, Trisquel 11 and Ubuntu 22.04 behave the same. The version of git in Debian 12, AlmaLinux/RockyLinux 8/9, Alpine, ArchLinux, macOS homebrew, and upcoming Ubuntu 24.04 behave in another way. Hopefully this will not change that often, but this would invalidate reproducibility of these tarballs in the future, forcing you to use an old git release to reproduce the source-only tarball. Alas, GitLab and most other sites appears to be using modern git so the download tarballs from them would not match my tarballs – even though the content would.
Side note on ChangeLog: ChangeLog files were traditionally manually curated files with version history for a package. In recent years, several projects moved to dynamically generate them from git history (using tools like git2cl or gitlog-to-changelog). This has consequences for reproducibility of tarballs: you need to have the entire git history available! The gitlog-to-changelog tool also output different outputs depending on the time zone of the person using it, which arguable is a simple bug that can be fixed. However this entire approach is incompatible with rebuilding the full tarball from the minimal source-only tarball. It seems Libntlm’s ChangeLog file died on the surgery table here.
So how would a distribution build these minimal source-only tarballs? I happen to help on the libntlm package in Debian. It has historically used the generated tarballs as the source code to build from. This means that code coming from gnulib is vendored in the tarball. When a security problem is discovered in gnulib code, the security team needs to patch all packages that include that vendored code and rebuild them, instead of merely patching the gnulib package and rebuild all packages that rely on that particular code. To change this, the Debian libntlm package needs to Build-Depends on Debian’s gnulib package. But there was one problem: similar to most projects that use gnulib, Libntlm depend on a particular git commit of gnulib, and Debian only ship one commit. There is no coordination about which commit to use. I have adopted gnulib in Debian, and add a git bundle to the *_all.deb binary package so that projects that rely on gnulib can pick whatever commit they need. This allow an no-network GNULIB_URL and GNULIB_REVISION approach when running Libntlm’s ./bootstrap with the Debian gnulib package installed. Otherwise libntlm would pick up whatever latest version of gnulib that Debian happened to have in the gnulib package, which is not what the Libntlm maintainer intended to be used, and can lead to all sorts of version mismatches (and consequently security problems) over time. Libntlm in Debian is developed and tested on Salsa and there is continuous integration testing of it as well, thanks to the Salsa CI team.
Side note on git bundles: unfortunately there appears to be no reproducible way to export a git repository into one or more files. So one unfortunate consequence of all this work is that the gnulib *.orig.tar.gz tarball in Debian is not reproducible any more. I have tried to get Git bundles to be reproducible but I never got it to work — see my notes in gnulib’s debian/README.source on this aspect. Of course, source tarball reproducibility has nothing to do with binary reproducibility of gnulib in Debian itself, fortunately.
One open question is how to deal with the increased build dependencies that is triggered by this approach. Some people are surprised by this but I don’t see how to get around it: if you depend on source code for tools in another package to build your package, it is a bad idea to hide that dependency. We’ve done it for a long time through vendored code in non-minimal tarballs. Libntlm isn’t the most critical project from a bootstrapping perspective, so adding git and gnulib as Build-Depends to it will probably be fine. However, consider if this pattern was used for other packages that uses gnulib such as coreutils, gzip, tar, bison etc (all are using gnulib) then they would all Build-Depends on git and gnulib. Cross-building those packages for a new architecture will therefor require git on that architecture first, which gets circular quick. The dependency on gnulib is real so I don’t see that going away, and gnulib is a Architecture:all package. However, the dependency on git is merely a consequence of how the Debian gnulib package chose to make all gnulib git commits available to projects: through a git bundle. There are other ways to do this that doesn’t require the git tool to extract the necessary files, but none that I found practical — ideas welcome!
Finally some brief notes on how this was implemented. Enabling bootstrappable source-only minimal tarballs via gnulib’s ./bootstrap is achieved by using the GNULIB_REVISION mechanism, locking down the gnulib commit used. I have always disliked git submodules because they add extra steps and has complicated interaction with CI/CD. The reason why I gave up git submodules now is because the particular commit to use is not recorded in the git archive output when git submodules is used. So the particular gnulib commit has to be mentioned explicitly in some source code that goes into the git archive tarball. Colin Watson added the GNULIB_REVISION approach to ./bootstrap back in 2018, and now it no longer made sense to continue to use a gnulib git submodule. One alternative is to use ./bootstrap with --gnulib-srcdir or --gnulib-refdir if there is some practical problem with the GNULIB_URL towards a git bundle the GNULIB_REVISION in bootstrap.conf.
git archive --prefix=libntlm-v1.8/ -o libntlm-v1.8.tar.gz HEAD
Making the make dist generated tarball reproducible can be more complicated, however for Libntlm it was sufficient to make sure the modification times of all files were set deterministically to the timestamp of the last commit in the git repository. Interestingly there seems to be a couple of different ways to accomplish this, Guix doesn’t support minimal source-only tarballs but rely on a .tarball-timestamp file inside the tarball. Paul Eggert explained what TZDB is using some time ago. The approach I’m using now is fairly similar to the one I suggested over a year ago. If there are problems because all files in the tarball now use the same modification time, there is a solution by Bruno Haible that could be implemented.
Side note on git tags: Some people may wonder why not verify a signed git tag instead of verifying a signed tarball of the git archive. Currently most git repositories uses SHA-1 for git commit identities, but SHA-1 is not a secure hash function. While current SHA-1 attacks can be detected and mitigated, there are fundamental doubts that a git SHA-1 commit identity uniquely refers to the same content that was intended. Verifying a git tag will never offer the same assurance, since a git tag can be moved or re-signed at any time. Verifying a git commit is better but then we need to trust SHA-1. Migrating git to SHA-256 would resolve this aspect, but most hosting sites such as GitLab and GitHub does not support this yet. There are other advantages to using signed tarballs instead of signed git commits or git tags as well, e.g., tar.gz can be a deterministically reproducible persistent stable offline storage format but .git sub-directory trees or git bundles do not offer this property.
Doing continous testing of all this is critical to make sure things don’t regress. Libntlm’s pipeline definition now produce the generated libntlm-*.tar.gz tarballs and a checksum as a build artifact. Then I added the 000-reproducability job which compares the checksums and fails on mismatches. You can read its delicate output in the job for the v1.8 release. Right now we insists that builds on Trisquel 11 match Ubuntu 22.04, that PureOS 10 builds match Debian 11 builds, that AlmaLinux 8 builds match RockyLinux 8 builds, and AlmaLinux 9 builds match RockyLinux 9 builds. As you can see in pipeline job output, not all platforms lead to the same tarballs, but hopefully this state can be improved over time. There is also partial reproducibility, where the full tarball is reproducible across two distributions but not the minimal tarball, or vice versa.
If this way of working plays out well, I hope to implement it in other projects too.
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
write build-ids to debian binary control files,
so that the build-id (more specifically, the ELF note
.note.gnu.build-id) wound up in the Debian apt archive metadata.
I’ve always thought this was super cool, and seeing as how Michael Stapelberg
blogged
some great pointers around the ecosystem, including the fancy new debuginfod
service, and the
find-dbgsym-packages
helper, which uses these same headers, I don’t think I’m the only one.
At work I’ve been using a lot of rust,
specifically, async rust using tokio. To try and work on
my style, and to dig deeper into the how and why of the decisions made in these
frameworks, I’ve decided to hack up a project that I’ve wanted to do ever
since 2015 – write a debug filesystem. Let’s get to it.
Back to the Future
Time to admit something. I really love Plan 9. It’s
just so good. So many ideas from Plan 9 are just so prescient, and everything
just feels right. Not just right like, feels good – like, correct. The
bit that I’ve always liked the most is 9p, the network protocol for serving
a filesystem over a network. This leads to all sorts of fun programs, like the
Plan 9 ftp client being a 9p server – you mount the ftp server and access
files like any other files. It’s kinda like if fuse were more fully a part
of how the operating system worked, but fuse is all running client-side. With
9p there’s a single client, and different servers that you can connect to,
which may be backed by a hard drive, remote resources over something like SFTP, FTP, HTTP or even purely synthetic.
The interesting (maybe sad?) part here is that 9p wound up outliving Plan 9
in terms of adoption – 9p is in all sorts of places folks don’t usually expect.
For instance, the Windows Subsystem for Linux uses the 9p protocol to share
files between Windows and Linux. ChromeOS uses it to share files with Crostini,
and qemu uses 9p (virtio-p9) to share files between guest and host. If you’re
noticing a pattern here, you’d be right; for some reason 9p is the go-to protocol
to exchange files between hypervisor and guest. Why? I have no idea, except maybe
due to being designed well, simple to implement, and it’s a lot easier to validate the data being shared
and validate security boundaries. Simplicity has its value.
As a result, there’s a lot of lingering 9p support kicking around. Turns out
Linux can even handle mounting 9p filesystems out of the box. This means that I
can deploy a filesystem to my LAN or my localhost by running a process on top
of a computer that needs nothing special, and mount it over the network on an
unmodified machine – unlike fuse, where you’d need client-specific software
to run in order to mount the directory. For instance, let’s mount a 9p
filesystem running on my localhost machine, serving requests on 127.0.0.1:564
(tcp) that goes by the name “mountpointname” to /mnt.
Linux will mount away, and attach to the filesystem as the root user, and by default,
attach to that mountpoint again for each local user that attempts to use
it. Nifty, right? I think so. The server is able
to keep track of per-user access and authorization
along with the host OS.
WHEREIN I STYX WITH IT
Since I wanted to push myself a bit more with rust and tokio specifically,
I opted to implement the whole stack myself, without third party libraries on
the critical path where I could avoid it. The 9p protocol (sometimes called
Styx, the original name for it) is incredibly simple. It’s a series of client
to server requests, which receive a server to client response. These are,
respectively, “T” messages, which transmit a request to the server, which
trigger an “R” message in response (Reply messages). These messages are
TLV payload
with a very straight forward structure – so straight forward, in fact, that I
was able to implement a working server off nothing more than a handful of man
pages.
Later on after the basics worked, I found a more complete
spec page
that contains more information about the
unix specific variant
that I opted to use (9P2000.u rather than 9P2000) due to the level
of Linux specific support for the 9P2000.u variant over the 9P2000
protocol.
MR ROBOTO
The backend stack over at zoo is rust and tokio
running i/o for an HTTP and WebRTC server. I figured I’d pick something
fairly similar to write my filesystem with, since 9P can be implemented
on basically anything with I/O. That means tokio tcp server bits, which
construct and use a 9p server, which has an idiomatic Rusty API that
partially abstracts the raw R and T messages, but not so much as to
cause issues with hiding implementation possibilities. At each abstraction
level, there’s an escape hatch – allowing someone to implement any of
the layers if required. I called this framework
arigato which can be found over on
docs.rs and
crates.io.
/// Simplified version of the arigato File trait; this isn't actually
/// the same trait; there's some small cosmetic differences. The
/// actual trait can be found at:
///
/// https://docs.rs/arigato/latest/arigato/server/trait.File.html
trait File {
/// OpenFile is the type returned by this File via an Open call.
typeOpenFile: OpenFile;
/// Return the 9p Qid for this file. A file is the same if the Qid is
/// the same. A Qid contains information about the mode of the file,
/// version of the file, and a unique 64 bit identifier.
fnqid(&self) -> Qid;
/// Construct the 9p Stat struct with metadata about a file.
async fnstat(&self) -> FileResult<Stat>;
/// Attempt to update the file metadata.
async fnwstat(&mut self, s: &Stat) -> FileResult<()>;
/// Traverse the filesystem tree.
async fnwalk(&self, path: &[&str]) -> FileResult<(Option<Self>, Vec<Self>)>;
/// Request that a file's reference be removed from the file tree.
async fnunlink(&mut self) -> FileResult<()>;
/// Create a file at a specific location in the file tree.
async fncreate(
&mut self,
name: &str,
perm: u16,
ty: FileType,
mode: OpenMode,
extension: &str,
) -> FileResult<Self>;
/// Open the File, returning a handle to the open file, which handles
/// file i/o. This is split into a second type since it is genuinely
/// unrelated -- and the fact that a file is Open or Closed can be
/// handled by the `arigato` server for us.
async fnopen(&mut self, mode: OpenMode) -> FileResult<Self::OpenFile>;
}
/// Simplified version of the arigato OpenFile trait; this isn't actually
/// the same trait; there's some small cosmetic differences. The
/// actual trait can be found at:
///
/// https://docs.rs/arigato/latest/arigato/server/trait.OpenFile.html
trait OpenFile {
/// iounit to report for this file. The iounit reported is used for Read
/// or Write operations to signal, if non-zero, the maximum size that is
/// guaranteed to be transferred atomically.
fniounit(&self) -> u32;
/// Read some number of bytes up to `buf.len()` from the provided
/// `offset` of the underlying file. The number of bytes read is
/// returned.
async fnread_at(
&mut self,
buf: &mut [u8],
offset: u64,
) -> FileResult<u32>;
/// Write some number of bytes up to `buf.len()` from the provided
/// `offset` of the underlying file. The number of bytes written
/// is returned.
fnwrite_at(
&mut self,
buf: &mut [u8],
offset: u64,
) -> FileResult<u32>;
}
Thanks, decade ago paultag!
Let’s do it! Let’s use arigato to implement a 9p filesystem we’ll call
debugfs that will serve all the debug
files shipped according to the Packages metadata from the apt archive. We’ll
fetch the Packages file and construct a filesystem based on the reported
Build-Id entries. For those who don’t know much about how an apt repo
works, here’s the 2-second crash course on what we’re doing. The first is to
fetch the Packages file, which is specific to a binary architecture (such as
amd64, arm64 or riscv64). That architecture is specific to a
component (such as main, contrib or non-free). That component is
specific to a suite, such as stable, unstable or any of its aliases
(bullseye, bookworm, etc). Let’s take a look at the Packages.xz file for
the unstable-debugsuite, maincomponent, for all amd64 binaries.
This will return the Debian-style
rfc2822-like headers,
which is an export of the metadata contained inside each .deb file which
apt (or other tools that can use the apt repo format) use to fetch
information about debs. Let’s take a look at the debug headers for the
netlabel-tools package in unstable – which is a package named
netlabel-tools-dbgsym in unstable-debug.
So here, we can parse the package headers in the Packages.xz file, and store,
for each Build-Id, the Filename where we can fetch the .deb at. Each
.deb contains a number of files – but we’re only really interested in the
files inside the .deb located at or under /usr/lib/debug/.build-id/,
which you can find in debugfs under
rfc822.rs. It’s
crude, and very single-purpose, but I’m feeling a bit lazy.
Who needs dpkg?!
For folks who haven’t seen it yet, a .deb file is a special type of
.ar file, that contains (usually)
three files inside – debian-binary, control.tar.xz and data.tar.xz.
The core of an .ar file is a fixed size (60 byte) entry header,
followed by the specified size number of bytes.
[8 byte .ar file magic]
[60 byte entry header]
[N bytes of data]
[60 byte entry header]
[N bytes of data]
[60 byte entry header]
[N bytes of data]
...
First up was to implement a basic ar parser in
ar.rs. Before we get
into using it to parse a deb, as a quick diversion, let’s break apart a .deb
file by hand – something that is a bit of a rite of passage (or at least it
used to be? I’m getting old) during the Debian nm (new member) process, to take
a look at where exactly the .debug file lives inside the .deb file.
$ ar x netlabel-tools-dbgsym_0.30.0-1+b1_amd64.deb
$ ls
control.tar.xz debian-binary
data.tar.xz netlabel-tools-dbgsym_0.30.0-1+b1_amd64.deb
$ tar --list -f data.tar.xz | grep '.debug$'
./usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
Since we know quite a bit about the structure of a .deb file, and I had to
implement support from scratch anyway, I opted to implement a (very!) basic
debfile parser using HTTP Range requests. HTTP Range requests, if supported by
the server (denoted by a accept-ranges: bytes HTTP header in response to an
HTTP HEAD request to that file) means that we can add a header such as
range: bytes=8-68 to specifically request that the returned GET body be the
byte range provided (in the above case, the bytes starting from byte offset 8
until byte offset 68). This means we can fetch just the ar file entry from
the .deb file until we get to the file inside the .deb we are interested in
(in our case, the data.tar.xz file) – at which point we can request the body
of that file with a final range request. I wound up writing a struct to
handle a read_at-style API surface in
hrange.rs, which
we can pair with ar.rs above and start to find our data in the .deb remotely
without downloading and unpacking the .deb at all.
After we have the body of the data.tar.xz coming back through the HTTP
response, we get to pipe it through an xz decompressor (this kinda sucked in
Rust, since a tokioAsyncRead is not the same as an http Body response is
not the same as std::io::Read, is not the same as an async (or sync)
Iterator is not the same as what the xz2 crate expects; leading me to read
blocks of data to a buffer and stuff them through the decoder by looping over
the buffer for each lzma2 packet in a loop), and tarfile parser (similarly
troublesome). From there we get to iterate over all entries in the tarfile,
stopping when we reach our file of interest. Since we can’t seek, but gdb
needs to, we’ll pull it out of the stream into a Cursor<Vec<u8>> in-memory
and pass a handle to it back to the user.
I was originally hoping to avoid transferring the whole tar file over the
network (and therefore also reading the whole debug file into ram, which
objectively sucks), but quickly hit issues with figuring out a way around
seeking around an xz file. What’s interesting is xz has a great primitive
to solve this specific problem (specifically, use a block size that allows you
to seek to the block as close to your desired seek position just before it,
only discarding at most block size - 1 bytes), but data.tar.xz files
generated by dpkg appear to have a single mega-huge block for the whole file.
I don’t know why I would have expected any different, in retrospect. That means
that this now devolves into the base case of “How do I seek around an lzma2
compressed data stream”; which is a lot more complex of a question.
Thankfully, notoriously brilliant tianon was
nice enough to introduce me to Jon Johnson
who did something super similar – adapted a technique to seek inside a
compressed gzip file, which lets his service
oci.dag.dev
seek through Docker container images super fast based on some prior work
such as soci-snapshotter, gztool, and
zran.c.
He also pulled this party trick off for apk based distros
over at apk.dag.dev, which seems apropos.
Jon was nice enough to publish a lot of his work on this specifically in a
central place under the name “targz”
on his GitHub, which has been a ton of fun to read through.
The gist is that, by dumping the decompressor’s state (window of previous
bytes, in-memory data derived from the last N-1 bytes) at specific
“checkpoints” along with the compressed data stream offset in bytes and
decompressed offset in bytes, one can seek to that checkpoint in the compressed
stream and pick up where you left off – creating a similar “block” mechanism
against the wishes of gzip. It means you’d need to do an O(n) run over the
file, but every request after that will be sped up according to the number
of checkpoints you’ve taken.
Given the complexity of xz and lzma2, I don’t think this is possible
for me at the moment – especially given most of the files I’ll be requesting
will not be loaded from again – especially when I can “just” cache the debug
header by Build-Id. I want to implement this (because I’m generally curious
and Jon has a way of getting someone excited about compression schemes, which
is not a sentence I thought I’d ever say out loud), but for now I’m going to
move on without this optimization. Such a shame, since it kills a lot of the
work that went into seeking around the .deb file in the first place, given
the debian-binary and control.tar.gz members are so small.
The Good
First, the good news right? It works! That’s pretty cool. I’m positive
my younger self would be amused and happy to see this working; as is
current day paultag. Let’s take debugfs out for a spin! First, we need
to mount the filesystem. It even works on an entirely unmodified, stock
Debian box on my LAN, which is huge. Let’s take it for a spin:
And, let’s prove to ourselves that this actually mounted before we go
trying to use it:
$ mount | grep build-id
192.168.0.2 on /usr/lib/debug/.build-id type 9p (rw,relatime,aname=unstable-debug,access=user,trans=tcp,version=9p2000.u,port=564)
Slick. We’ve got an open connection to the server, where our host
will keep a connection alive as root, attached to the filesystem provided
in aname. Let’s take a look at it.
$ ls /usr/lib/debug/.build-id/
00 0d 1a 27 34 41 4e 5b 68 75 82 8E 9b a8 b5 c2 CE db e7 f3
01 0e 1b 28 35 42 4f 5c 69 76 83 8f 9c a9 b6 c3 cf dc E7 f4
02 0f 1c 29 36 43 50 5d 6a 77 84 90 9d aa b7 c4 d0 dd e8 f5
03 10 1d 2a 37 44 51 5e 6b 78 85 91 9e ab b8 c5 d1 de e9 f6
04 11 1e 2b 38 45 52 5f 6c 79 86 92 9f ac b9 c6 d2 df ea f7
05 12 1f 2c 39 46 53 60 6d 7a 87 93 a0 ad ba c7 d3 e0 eb f8
06 13 20 2d 3a 47 54 61 6e 7b 88 94 a1 ae bb c8 d4 e1 ec f9
07 14 21 2e 3b 48 55 62 6f 7c 89 95 a2 af bc c9 d5 e2 ed fa
08 15 22 2f 3c 49 56 63 70 7d 8a 96 a3 b0 bd ca d6 e3 ee fb
09 16 23 30 3d 4a 57 64 71 7e 8b 97 a4 b1 be cb d7 e4 ef fc
0a 17 24 31 3e 4b 58 65 72 7f 8c 98 a5 b2 bf cc d8 E4 f0 fd
0b 18 25 32 3f 4c 59 66 73 80 8d 99 a6 b3 c0 cd d9 e5 f1 fe
0c 19 26 33 40 4d 5a 67 74 81 8e 9a a7 b4 c1 ce da e6 f2 ff
Outstanding. Let’s try using gdb to debug a binary that was provided by
the Debian archive, and see if it’ll load the ELF by build-id from the
right .deb in the unstable-debug suite:
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
(gdb)
Yes! Yes it will!
$ file /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
/usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter *empty*, BuildID[sha1]=e59f81f6573dadd5d95a6e4474d9388ab2777e2a, for GNU/Linux 3.2.0, with debug_info, not stripped
The Bad
Linux’s support for 9p is mainline, which is great, but it’s not robust.
Network issues or server restarts will wedge the mountpoint (Linux can’t
reconnect when the tcp connection breaks), and things that work fine on local
filesystems get translated in a way that causes a lot of network chatter – for
instance, just due to the way the syscalls are translated, doing an ls, will
result in a stat call for each file in the directory, even though linux had
just got a stat entry for every file while it was resolving directory names.
On top of that, Linux will serialize all I/O with the server, so there’s no
concurrent requests for file information, writes, or reads pending at the same
time to the server; and read and write throughput will degrade as latency
increases due to increasing round-trip time, even though there are offsets
included in the read and write calls. It works well enough, but is
frustrating to run up against, since there’s not a lot you can do server-side
to help with this beyond implementing the 9P2000.L variant (which, maybe is
worth it).
The Ugly
Unfortunately, we don’t know the file size(s) until we’ve actually opened the
underlying tar file and found the correct member, so for most files, we don’t
know the real size to report when getting a stat. We can’t parse the tarfiles
for every stat call, since that’d make ls even slower (bummer). Only
hiccup is that when I report a filesize of zero, gdb throws a bit of a
fit; let’s try with a size of 0 to start:
$ ls -lah /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
-r--r--r-- 1 root root 0 Dec 31 1969 /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
warning: Discarding section .note.gnu.build-id which has a section size (24) larger than the file size [in module /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug]
[...]
This obviously won’t work since gdb will throw away all our hard work because
of stat’s output, and neither will loading the real size of the underlying
file. That only leaves us with hardcoding a file size and hope nothing else
breaks significantly as a result. Let’s try it again:
$ ls -lah /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
-r--r--r-- 1 root root 954M Dec 31 1969 /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
(gdb)
Much better. I mean, terrible but better. Better for now, anyway.
Kilroy was here
Do I think this is a particularly good idea? I mean; kinda. I’m probably going
to make some fun 9parigato-based filesystems for use around my LAN, but I
don’t think I’ll be moving to use debugfs until I can figure out how to
ensure the connection is more resilient to changing networks, server restarts
and fixes on i/o performance. I think it was a useful exercise and is a pretty
great hack, but I don’t think this’ll be shipping anywhere anytime soon.
Along with me publishing this post, I’ve pushed up all my repos; so you
should be able to play along at home! There’s a lot more work to be done
on arigato; but it does handshake and successfully export a working
9P2000.u filesystem. Check it out on on my github at
arigato,
debugfs
and also on crates.io
and docs.rs.
At least I can say I was here and I got it working after all these years.
When I first started studying computer science setting up a programming project was easy, write source code files and a Makefile and that was it. IRC was the only IM system and email was the only other communications system that was used much. Writing Makefiles is difficult but products like the Borland Turbo series of IDEs did all that for you so you could just start typing code and press a function key to compile and run (F5 from memory).
Over the years the requirements and expectations of computer use have grown significantly. The typical office worker is now doing many more things with computers than serious programmers used to do. Running an IM system, an online document editing system, and a series of web apps is standard for companies nowadays. Developers have to do all that in addition to tools for version control, continuous integration, bug reporting, and feature tracking. The development process is also more complex with extra steps for reproducible builds, automated tests, and code coverage metrics for the tests. I wonder how many programmers who started in the 90s would have done something else if faced with Github as their introduction.
How much of this is good? Having the ability to send instant messages all around the world is great. Having dozens of different ways of doing so is awful. When a company uses multiple IM systems such as MS-Teams and Slack and forces some of it’s employees to use them both it’s getting ridiculous. Having different friend groups on different IM systems is anti-social networking. In the EU the Digital Markets Act [1] forces some degree of interoperability between different IM systems and as it’s impossible to know who’s actually in the EU that will end up being world-wide.
In corporations document management often involves multiple ways of storing things, you have Google Docs, MS Office online, hosted Wikis like Confluence, and more. Large companies tend to use several such systems which means that people need to learn multiple systems to be able to work and they also need to know which systems are used by the various groups that they communicate with. Microsoft deserves some sort of award for the range of ways they have for managing documents, Sharepoint, OneDrive, Office Online, attachments to Teams rooms, and probably lots more.
During WW2 the predecessor to the CIA produced an excellent manual for simple sabotage [2]. If something like that was written today the section General Interference with Organisations and Production would surely have something about using as many incompatible programs and web sites as possible in the work flow. The proliferation of software required for work is a form of denial of service attack against corporations.
The efficiency of companies doesn’t really bother me. It sucks that companies are creating a demoralising workplace that is unpleasant for workers. But the upside is that the biggest companies are the ones doing the worst things and are also the most afflicted by these problems. It’s almost like the Bureau of Sabotage in some of Frank Herbert’s fiction [3].
The thing that concerns me is the effect of multiple standards on free software development. We have IRC the most traditional IM support system which is getting replaced by Matrix but we also have some projects using Telegram, and Jabber hasn’t gone away. I’m sure there are others too. There are also multiple options for version control (although github seems to dominate the market), forums, bug trackers, etc. Reporting bugs or getting support in free software often requires interacting with several of them. Developing free software usually involves dealing with the bug tracking and documentation systems of the distribution you use as well as the upstream developers of the software. If the problem you have is related to compatibility between two different pieces of free software then you can end up dealing with even more bug tracking systems.
There are real benefits to some of the newer programs to track bugs, write documentation, etc. There is also going to be a cost in changing which gives an incentive for the older projects to keep using what has worked well enough for them in the past,
How can we improve things? Use only the latest tools? Prioritise ease of use? Aim more for the entry level contributors?
I tried to upgrade bullseye machien to bookworm, so I got the following error:
File “/usr/lib/python3/dist-packages/django/contrib/auth/mixins.py”, line 5, in from django.contrib.auth.views import redirect_to_login File “/usr/lib/python3/dist-packages/django/contrib/auth/views.py”, line 20, in from django.utils.http import ( ImportError: cannot import name ‘url_has_allowed_host_and_scheme’ from ‘django.utils.http’ (/usr/lib/python3/dist-packages/django/utils/http.py)
During handling of the above exception, another exception occurred:
It is similar to #1000810, but it is already closed.
My solution is:
apt remove mailman3-web
keep db and config files (do not purge)
apt autoremove
remove django related packages
apt install mailman3-web mailman3-full
I tried to send to the report, but it rerutns `550 Unknown or archived bug’ …
I work from home these days, and my nearest office is over 100 miles away, 3 hours door to door if I travel by train (and, to be honest, probably not a lot faster given rush hour traffic if I drive). So I’m reliant on a functional internet connection in order to be able to work. I’m lucky to have access to Openreach FTTP, provided by Aquiss, but I worry about what happens if there’s a cable cut somewhere or some other long lasting problem. Worst case I could tether to my work phone, or try to find some local coworking space to use while things get sorted, but I felt like arranging a backup option was a wise move.
Step 1 turned out to be sorting out recursive DNS. It’s been many moons since I had to deal with running DNS in a production setting, and I’ve mostly done my best to avoid doing it at home too. dnsmasq has done a decent job at providing for my needs over the years, covering DHCP, DNS (+ tftp for my test device network). However I just let it slave off my ISP’s nameservers, which means if that link goes down it’ll no longer be able to resolve anything outside the house.
One option would have been to either point to a different recursive DNS server (Cloudfare’s 1.1.1.1 or Google’s Public DNS being the common choices), but I’ve no desire to share my lookup information with them. As another approach I could have done some sort of failover of resolv.conf when the primary network went down, but then I would have to get into moving files around based on networking status and that felt a bit clunky.
So I decided to finally setup a proper local recursive DNS server, which is something I’ve kinda meant to do for a while but never had sufficient reason to look into. Last time I did this I did it with BIND 9 but there are more options these days, and I decided to go with unbound, which is primarily focused on recursive DNS.
One extra wrinkle, pointed out by Lars, is that having dynamic name information from DHCP hosts is exceptionally convenient. I’ve kept dnsmasq as the local DHCP server, so I wanted to be able to forward local queries there.
I’m doing all of this on my RB5009, running Debian. Installing unbound was a simple matter of apt install unbound. I needed 2 pieces of configuration over the default, one to enable recursive serving for the house networks, and one to enable forwarding of queries for the local domain to dnsmasq. I originally had specified the wildcard address for listening, but this caused problems with the fact my router has many interfaces and would sometimes respond from a different address than the request had come in on.
server:
domain-insecure: "example.org"
do-not-query-localhost: no
forward-zone:
name: "example.org"
forward-addr: 127.0.0.1@5353
I then had to configure dnsmasq to not listen on port 53 (so unbound could), respond to requests on the loopback interface (I have dnsmasq restricted to only explicitly listed interfaces), and to hand out unbound as the appropriate nameserver in DHCP requests - once dnsmasq is not listening on port 53 it no longer does this by default.
With these minor changes in place I now have local recursive DNS being handled by unbound, without losing dynamic local DNS for DHCP hosts. As an added bonus I now get 10/10 on Test IPv6 - previously I was getting dinged on the ability for my DNS server to resolve purely IPv6 reachable addresses.
Welcome to the March 2024 report from the Reproducible Builds project! In our reports, we attempt to outline what we have been up to over the past month, as well as mentioning some of the important things happening more generally in software supply-chain security. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Arch Linux minimal container userland now 100% reproducible
In remarkable news, Reproducible builds developer kpcyrd reported that that the Arch Linux “minimal container userland” is now 100% reproducible after work by developers dvzv and Foxboron on the one remaining package. This represents a “real world”, widely-used Linux distribution being reproducible.
Their post, which kpcyrd suffixed with the question “now what?”, continues on to outline some potential next steps, including validating whether the container image itself could be reproduced bit-for-bit. The post, which was itself a followup for an Arch Linux update earlier in the month, generated a significant number of replies.
Validating Debian’s build infrastructure after the XZ backdoor
From our mailing list this month, Vagrant Cascadian wrote about being asked about trying to perform concrete reproducibility checks for recent Debian security updates, in an attempt to gain some confidence about Debian’s build infrastructure given that they performed builds in environments running the high-profile XZ vulnerability.
Vagrant reports (with some caveats):
So far, I have not found any reproducibility issues; everything I tested I was able to get to build bit-for-bit identical with what is in the
Debian archive.
That is to say, reproducibility testing permitted Vagrant and Debian to claim with some confidence that builds performed when this vulnerable version of XZ was installed were not interfered with.
Documented in more detail on Fedora’s website, the talk touched on topics such as the specifics of implementing reproducible builds in Fedora, the challenges encountered, the current status and what’s coming next. (YouTube video)
“Increasing Trust in the Open Source Supply Chain with Reproducible Builds and Functional Package Management”
Functional package managers (FPMs) and reproducible builds (R-B) are technologies and methodologies that are conceptually very different from the traditional software deployment model, and that have promising properties for software supply chain security. This thesis aims to evaluate the impact of FPMs and R-B on the security of the software supply chain and propose improvements to the FPM model to further improve trust in the open source supply chain. PDF
Julien’s paper poses a number of research questions on how the model of distributions such as GNU Guix and NixOS can “be leveraged to further improve the safety of the software supply chain”, etc.
Software and source code identification with GNU Guix and reproducible builds
In a long line of commendably detailed blog posts, Ludovic Courtès, Maxim Cournoyer, Jan Nieuwenhuizen and Simon Tournier have together published two interesting posts on the GNU Guix blog this month. In early March, Ludovic Courtès, Maxim Cournoyer, Jan Nieuwenhuizen and Simon Tournier wrote about software and source code identification and how that might be performed using Guix, rhetorically posing the questions: “What does it take to ‘identify software’? How can we tell what software is running on a machine to determine, for example, what security vulnerabilities might affect it?”
Later in the month, Ludovic Courtès wrote a solo post describing adventures on the quest for long-term reproducible deployment. Ludovic’s post touches on GNU Guix’s aim to support “time travel”, the ability to reliably (and reproducibly) revert to an earlier point in time, employing the iconic image of Harold Lloyd hanging off the clock in Safety Last! (1925) to poetically illustrate both the slapstick nature of current modern technology and the gymnastics required to navigate hazards of our own making.
Two new Rust-based tools for post-processing determinism
Zbigniew Jędrzejewski-Szmek announced add-determinism, a work-in-progress reimplementation of the Reproducible Builds project’s own strip-nondeterminism tool in the Rust programming language, intended to be used as a post-processor in RPM-based distributions such as Fedora
In Debian this month, since the testing framework no longer varies the build path, James Addison performed a bulk downgrade of the bug severity for issues filed with a level of normal to a new level of wishlist. In addition, 28 reviews of Debian packages were added, 38 were updated and 23 were removed this month adding to ever-growing knowledge about identified issues. As part of this effort, a number of issue types were updated, including Chris Lamb adding a new ocaml_include_directories toolchain issue […] and James Addison adding a new filesystem_order_in_java_jar_manifest_mf_include_resource issue […] and updating the random_uuid_in_notebooks_generated_by_nbsphinx to reference a relevant discussion thread […].
In addition, Roland Clobus posted his 24th status update of reproducible Debian ISO images. Roland highlights that the images for Debian unstable often cannot be generated due to changes in that distribution related to the 64-bit time_t transition.
Lastly, Bernhard M. Wiedemann posted another monthly update for his reproducibility work in openSUSE.
There were made a number of improvements to our website this month, including:
Pol Dellaiera noticed the frequent need to correctly cite the website itself in academic work. To facilitate easier citation across multiple formats, Pol contributed a Citation File Format (CIF) file. As a result, an export in BibTeX format is now available in the Academic Publications section. Pol encourages community contributions to further refine the CITATION.cff file. Pol also added an substantial new section to the “buy in” page documenting the role of Software Bill of Materials (SBOMs) and ephemeral development environments. […][…]
Bernhard M. Wiedemann added a new “commandments” page to the documentation […][…] and fixed some incorrect YAML elsewhere on the site […].
Chris Lamb add three recent academic papers to the publications page of the website. […]
Mattia Rizzolo and Holger Levsen collaborated to add Infomaniak as a sponsor of amd64 virtual machines. […][…][…]
Roland Clobus updated the “stable outputs” page, dropping version numbers from Python documentation pages […] and noting that Python’s set data structure is also affected by the PYTHONHASHSEED functionality. […]
Delta chat clients now reproducible
Delta Chat, an open source messaging application that can work over email, announced this month that the Rust-based core library underlying Delta chat application is now reproducible.
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 259, 260 and 261 to Debian and made the following additional changes:
New features:
Add support for the zipdetails tool from the Perl distribution. Thanks to Fay Stegerman and Larry Doolittle et al. for the pointer and thread about this tool. […]
Bug fixes:
Don’t identify Redis database dumps as GNU R database files based simply on their filename. […]
Add a missing call to File.recognizes so we actually perform the filename check for GNU R data files. […]
Don’t crash if we encounter an .rdb file without an equivalent .rdx file. (#1066991)
Correctly check for 7z being available—and not lz4—when testing 7z. […]
Prevent a traceback when comparing a contentful .pyc file with an empty one. […]
Testsuite improvements:
Fix .epub tests after supporting the new zipdetails tool. […]
Don’t use parenthesis within test “skipping…” messages, as PyTest adds its own parenthesis. […]
Factor out Python version checking in test_zip.py. […]
Skip some Zip-related tests under Python 3.10.14, as a potential regression may have been backported to the 3.10.x series. […]
Actually test 7z support in the test_7z set of tests, not the lz4 functionality. (Closes: reproducible-builds/diffoscope#359). […]
Chris Lamb also updated the trydiffoscope command line client, dropping a build-dependency on the deprecated python3-distutils package to fix Debian bug #1065988 […], taking a moment to also refresh the packaging to the latest Debian standards […]. Finally, Vagrant Cascadian submitted an update for diffoscope version 260 in GNU Guix. […]
Upstream patches
This month, we wrote a large number of patches, including:
Similarly, Jean-Pierre De Jesus DIAZ employed reproducible builds techniques in order to test a proposed refactor of the ath9k-htc-firmware package. As the change produced bit-for-bit identical binaries to the previously shipped pre-built binaries:
I don’t have the hardware to test this firmware, but the build produces the same hashes for the firmware so it’s safe to say that the firmware should keep working.
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In March, an enormous number of changes were made by Holger Levsen:
Initial work to clean up a messy NetBSD-related script. […][…]
Roland Clobus:
Show the installer log if the installer fails to build. […]
Avoid the minus character (i.e. -) in a variable in order to allow for tags in openQA. […]
Update the schedule of Debian live image builds. […]
Vagrant Cascadian:
Maintenance on the virt* nodes is completed so bring them back online. […]
Use the fully qualified domain name in configuration. […]
Node maintenance was also performed by Holger Levsen, Mattia Rizzolo […][…] and Vagrant Cascadian […][…][…][…]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
Last year a Debian Developer blogged about writing Haskell code to give a bad result for LLMs that were trained on it. I forgot who wrote the post and I’d appreciate the URL if anyone has it.
I respect such technical work to enforce one’s legal rights when they aren’t respected by corporations, but I have a different approach.
For what I write I am at this time happy to allow it to be used as part of a large training data set (consider this blog post a licence grant that applies until such time as I edit this post to change it). But only if aggregated with so much other data that my content is only a tiny portion of the data set by any metric. So I don’t want someone to make a programming LLM that has my code as the only C code or a political data set that has my blog posts as the only left-wing content. If someone wants to train an LLM on only my content to make a Russell-simulator then I don’t license my work for that purpose but also as it’s small enough that anyone with a bit of skill could do it on a weekend I can’t stop it. I would be really interested in seeing the results if someone from the FOSS community wanted to make a Russell-simulator and would probably issue them a license for such work if asked.
If my work comprises more than 0.1% of the content in a particular measure (theme, programming language, political position, etc) in a training data set then I don’t permit that without prior discussion.
Finally if someone wants to make a FOSS training data set to be used for FOSS LLM systems (maybe under the AGPL or some similar license) then I’ll allow my writing to be used as part of that.
Getting the Belgian eID to work on Linux
systems should be fairly easy, although some people do struggle with it.
For that reason, there is a lot of third-party documentation out there
in the form of blog posts, wiki pages, and other kinds of things.
Unfortunately, some of this documentation is simply wrong. Written by
people who played around with things until it kind of worked, sometimes
you get a situation where something that used to work in the past (but
wasn't really necessary) now stopped working, but it's still added to
a number of locations as though it were the gospel.
And then people follow these instructions and now things don't work
anymore.
OpenSC is an open source smartcard library that has support for a
pretty
large
number of smartcards, amongst which the Belgian eID. It provides a
PKCS#11 module as well as a
number of supporting tools.
For those not in the know, PKCS#11 is a standardized C API for
offloading cryptographic operations. It is an API that can be used when
talking to a hardware cryptographic module, in order to make that module
perform some actions, and it is especially popular in the open source
world, with support in
NSS,
amongst others. This library is written and maintained by mozilla, and
is a low-level cryptographic library that is used by Firefox (on all
platforms it supports) as well as by Google Chrome and other browsers
based on that (but only on Linux, and as I understand it, only for
linking with smartcards; their BoringSSL library is used for other
things).
The official eID software that we ship through
eid.belgium.be,
also known as "BeID", provides a PKCS#11 module for the Belgian eID, as
well as a number of support tools to make interacting with the card
easier, such as the "eID viewer", which provides the ability to read
data from the card, and validate their signatures. While the very first
public version of this eID PKCS#11 module was originally based on
OpenSC, it has since been reimplemented as a PKCS#11 module in its own
right, with no lineage to OpenSC whatsoever anymore.
About five years ago, the Belgian eID card was renewed. At the time, a
new physical appearance was the most obvious difference with the old
card, but there were also some technical, on-chip, differences that are
not so apparent. The most important one here, although it is not the
only one, is the fact that newer eID cards now use a NIST
P-384 elliptic curve-based private
keys, rather than the RSA-based
ones that were used in the past. This change required some changes to
any PKCS#11 module that supports the eID; both the BeID one, as well as
the OpenSC card-belpic driver that is written in support of the Belgian
eID.
Obviously, the required changes were implemented for the BeID module;
however, the OpenSC card-belpic driver was not updated. While I did do
some preliminary work on the required changes, I was unable to get it to
work, and eventually other things took up my time so I never finished
the implementation. If someone would like to finish the work that I
started, the preliminal patch that I
wrote
could be a good start -- but like I said, it doesn't yet work. Also,
you'll probably be interested in the official
documentation
of the eID card.
Unfortunately, in the mean time someone added the Applet 1.8 ATR to the
card-belpic.c file, without also implementing the required changes to
the driver so that the PKCS#11 driver actually supports the eID card.
The result of this is that if you have OpenSC installed in NSS for
either Firefox or any Chromium-based browser, and it gets picked up
before the BeID PKCS#11 module, then NSS will stop looking and pass all
crypto operations to the OpenSC PKCS#11 module rather than to the
official eID PKCS#11 module, and things will not work at all, causing a
lot of confusion.
I have therefore taken the following two steps:
The official eID packages now
conflict
with the OpenSC PKCS#11 module. Specifically only the PKCS#11 module,
not the rest of OpenSC, so you can theoretically still use its tools.
This means that once we release this new version of the eID software,
when you do an upgrade and you have OpenSC installed, it will remove
the PKCS#11 module and anything that depends on it. This is normal
and expected.
I have filed a pull
request against OpenSC
that removes the Applet 1.8 ATR from the driver, so that OpenSC will
stop claiming that it supports the 1.8 applet.
When the pull request is accepted, we will update the official eID
software to make the conflict versioned, so that as soon as it works
again you will again be able to install the OpenSC and BeID packages at
the same time.
In the mean time, if you have the OpenSC PKCS#11 module installed on
your system, and your eID authentication does not work, try removing it.
Some of my fellow Debian Developers (co-authors) started harassing
my family and I back in 2018 at a time when I lost two family members.
This blog has been written under duress. Normally the best thing to
do with bullies is to ignore them but they are blackmailing me with the
threat that WIPO will publish some insults denouncing me,
destroying my life and trying to push me into the
Debian suicide cluster.
Trigger warning
The Debian online community makes malicious references
to harassment and abuse, deliberately conflating different meanings of
these words to sully the reputations of independent volunteers. Victims
and witnesses to real harassment and abuse may be triggered
by exposure to these word games in the Debian online community.
Background
The misfits have now used Software in the Public Interest, Inc,
an organization that I have no relationship with, to transmit insults
through WIPO.
Some people may think that after more than three decades that I
have been doing voluntary work in ham radio and free, open source software,
this must be some kind of April Fool's Day joke. Sadly it is not.
The case says a lot about the toxic culture of these small-minded
people who are using the trademark to cling onto the coat-tails of
Debian's founders.
It is glaring at us in the list of domains in dispute. While these
misfits spend all their time slinking around in chat channels
jealously sneering at the real developers, I was the only one engaged
in creative thought registering some of the most exciting Debian-inspired
domain names. To prove the point, here is the list of domain names now
in dispute. Given all the effort they put into the debian.community
vendettas, why did none of the misfits spare a minute to think of any of
these names and register them first?
The list of domains is startling but at the same time, it captures
all the most contentious political issues in Debian today.
I feel that I have done the real community a huge service by thinking
ahead and registering these domains before they could fall into the
hands of cybersquatters.
Criminal proceedings in progress
There are now a range of criminal proceedings in progress regarding
the harassment of my family and I.
The outgoing Debian Project Leader has used his final email
newsletter to distribute defamation about police involvement.
This demonstrates the real motive of the WIPO insults is to use
all forms of proceedings concurrently, with as much noise about it as
possible, to cause the maximum stress and psychological harm to victims
such as my family and I and other independent volunteers.
The current harassment through the WIPO process is a violation of
UDRP Rules 15(e) regarding the harassment of the
domain name holder.
The outcome of criminal proceedings may help to test the
evidence submitted by the parties, to fill the deliberate gaps
in the evidence and to give some indication of the real source of
bad faith and previous patterns of harassment against my family and I.
I believe the panel should suspend the current procedure and
wait for the parties to provide details of the criminal proceedings
to the panel.
1.
Expresses respect for all victims of totalitarian and undemocratic regimes in Europe and pays tribute to those who fought against tyranny and oppression;
In point 4, the European Parliament asserts that
constant vigilance is needed to fight undemocratic, xenophobic,
authoritarian and totalitarian ideas and tendencies. Inspired by
this bi-partisan resolution from the European Parliament, I created the
web site Nazi.Compare and started publishing
examples of poor behavior by the vigilantes in free, open source
software communities.
Moreover, 2 April is Carla's birthday. The manner in which rogue
Debianists and toxic people at WIPO demand that I shift my focus to their petty
concerns is another prime example of the way that Debian fascism
(Debianism) is imposing on our families and personal lives.
Carla was born in Chile on the very day that Argentina launched their
doomed invasion of
Las Islas Malvinas / Falkland Islands. Carla's country, Chile,
who share a 4000km land border with Argentina, sided with the British
and allowed British forces to operate from Chilean territory.
Margarita Manterola (marga), who is Argentinian,
banned Carla from food at DebConf, despite the fact that Marga
has attended numerous DebConfs with her husband. Just another example
of how these two-faced people behave.
WIPO, Modern Slavery and Blackmail in Switzerland
The deadline also coincides with the Easter long weekend. While
other people are able to rest on the long weekend, these people are
blackmailing me to focus on my work with Debian, which is a voluntary
activity.
Blackmail is accompanied with a threat of adverse consequences.
In many countries, blackmail is a crime.
Forcing people to work without payment is a crime.
WIPO operates this blackmail with the threat that if I do not
spend Easter reading their insults and sit here working on this response,
they will automatically re-publish insults
and defamation, dragging the name of my family through the mud.
In other words, WIPO are revealing themselves to be a fascist
regime, a lot like those regimes that the European Parliament resolution
is warning us about.
I have already done decades of voluntary work for Debian and free,
open source software and now they force me to work on a public holiday.
The insults misfits submitted through WIPO regurgitate references to
harassment, abuse and 2018, the time when the trial of Cardinal George Pell
was underway, among other things.
Normally, when cases of abuse appear in the news,
the identities of victims, possible victims, witnesses, any other children
who were there and anybody in proximity to the children is obfuscated.
Yet Google, WIPO and Debian seem to be able to do as they please
and spread rumors about harassment and abuse of anonymous victims
in proximity to the volunteer developers.
The WIPO UDRP process makes no reference to how they protect the privacy
of people in proximity to potential cases of abuse.
I contacted various lawyers about the matter, this is an example
of one response from a firm registered with the bar association
in Ireland:
We are a small firm and our resources are quite stretched at this time.
Nonetheless, one of the architects of the cover-up in Melbourne has been
linked to Ireland.
Response being prepared without legal representation
In 2021, my business purchased a legal protection insurance from the
firm Parreaux, Thiebaud & Partners in Switzerland. It turns out this
firm had been operating in Switzerland since 2018 without a license
to sell insurance and without all but one or two staff having a law
license. In other words, from the perspective of the clients, the
Swiss insurance was no better than a ponzi scheme. Even more disturbing,
the Swiss authorities, including the financial regulator FINMA and
the Ordre des Avocats de Genève (Geneva Bar Association)
apparently knew about this since 2021 but didn't close the firm down
until 2023. It is the
Swiss JuristGate affair.
In some countries, like South Africa, home of the outgoing
Debian Project Leader Jonathan Carter, you can pay less than that to
have somebody killed.
No faith in WIPO, the legal panel, conflicts of interest
In the previous WeMakeFedora.org dispute, the ADR Forum
proposed a legal panelist who had a leading role in a trade association
promoting the interests of the complainant.
That particular conflict of interest was very easy to recognize
and the panelist withdrew from the process.
Many of the panelists appear to be associated with companies who
have funded one of the parties and some of them appear to be involved
in groups like the
FSFE Legal Network. At the same time, many of the current
vendettas appear to intersect with both FSFE and Debian at the same time.
Therefore, without being able to determine the extent to which any
particular panelist or WIPO employee is engaged in these other groups,
I do not trust any of them.
Jurisdiction and cultural issues
The WIPO documents specify a jurisdiction for the domain registrar
but the content on the web sites needs to be viewed through the
perspective of different jurisdictions and cultural conventions.
The Debian co-authors today come from a
range of different countries
each having their own legal and cultural expectations about matters such
as copyright, privacy and abuse.
There is a widespread understanding that the free, open source
software community values freedom of expression in the sense of the
first amendment to the US constitution / US Bill of Rights.
When people look at the
Debian Social Contract, which includes the
clause (3) We will not hide problems, there is an expectation that
we have all agreed to collaborate under an American regime of transparency
and free speech about organizational issues.
The role of Debian Project Leader has been performed by people from a
range of different countries where norms differ from one country to the
next. For example, Chris Lamb, who started the current vendetta in 2018,
is from the UK. It has been quite normal for the British press to
publish information about the former Mayor of London trying to help
girlfriends get jobs in the public service. Asking similar questions
about women who won internships in proximity to Chris Lamb feels entirely
compatible with the convention followed in British society.
In other European countries, such as Germany and Switzerland,
there seems to be far more emphasis on protecting the reputations
of those who are party to such affairs such that the whole affair
is often hidden from view. There is a perception that people from
these countries want to have their cake and eat it too. They
demand privacy for themselves but they still lurk on the
debian-private mailing list and chat channels spreading rumors
about the rest of us. They want to download and use the software without
paying for it and they don't even respect the principles of the developers.
The FSFE is even using a name derived from the American FSF, it
is feels like
a case of identity theft,
but at the same time they are snubbing freedom of expression.
Content that appears to be inconvenient for an entirely
German online community is quite valid in an online community claiming to
adhere to an American style of discourse.
Similarity of the domain names
It is clear that most of the domain names are either identical to
the trademark or they contain the trademark.
Total similarity is completely normal and inevitable because the
misfits behind the WIPO insults and I are all collectively co-authors
of the same Debian software that is identified by the trademark.
Some of the names, such as debianproject.org may appear
to be particularly audacious. Nonetheless, I do not expect the
legal panel to be the first to approve such a name. The previous case
D2000-0410 Religious Technology Center v. Freie Zone E. V.
concerned the domain scientologie.org which is totally
identical to the German spelling of the trademark. The case
was decided on the merits of legitimate interests. The
incredible similarity was not a black mark against the choice of
domain name.
It is odd that the misfits have
spent $120,000 on legal cases
to censor domain names but they couldn't think of any of these
names and register them in advance.
Money can buy legal harassment but it seems money can't replace
the creative minds that have abandoned Debian long ago.
Legitimate interests to use the trademark
There are various grounds providing Debian co-authors with a legitimate
interest to use the trademark in a domain name and in other contexts.
Legal counsel representing the misfits have submitted to WIPO
a copy of a previous WIPO censorship decree discussing the
scientologie.org dispute. Therefore, I presume that the
misfits and their legal counsel are aware of the arguments relating
to the scientologie.org verdict
(
WIPO UDRP case D2000-0410).
The outcome in the scientologie.org verdict is that somebody
having a copyright interest in a creative work that shares the name
of a trademark, that person has a legitimate interest in using the
name of the creative work in a domain name and possibly other contexts too.
By submitting the document, they implicitly acknowledge the open questions
from the previous legal panel.
The respondent to the previous dispute was an anonymous non-profit
organization, the Free Software Contributors Association. The
association asserted that some of their members were Debian Developers
wishing to protect their anonymity and privacy. In relation to whether
or not those people are real Debian Developers, the panel wrote:
The Panel confirms that this finding does not imply
that it has taken any view of the ownership of copyright in DEBIAN
software. Indeed, it is unable to do so on the evidence before it.
The panel did not seek to speculate on the names of the authors
contributing to the site but the misfits have been hysterical in
their finger pointing. After stealing that domain, the only thing
they used it for was publishing attack pages. In other words,
they violated UDRP rule 15(e) after the procedure had completed.
These two lines from that panel are significant and as the misfits have
submitted this document in support of their demands, with the help of
legal counsel, we are surprised they have not tried to answer that question
proactively. It appears that they don't care too much about documenting
and protecting the exclusive economic rights of a copyright owner or
the moral rights of an author.
On the distinction between the exclusive economic rights of a copyright
owner, I note that none of us Debian Developers, being the co-authors
of Debian, have ever been asked to assign our rights to any third-party
copyright owner. The misfits have not submitted any evidence purporting
to prove that such an assignment did take place. Therefore, there is no
copyright owner having exclusive economic rights over the Debian software.
By default, the rights rest with the authors who did the work. Despite
having clearly
read the panel's comments, the misfits have not submitted any evidence
claiming that any such party exists with exclusive economic rights
as a copyright owner of the Debian software.
Legitimate interest: a very long history of voluntary contribution
Some of us started doing Debian as a hobby alongside other hobbies
such as amateur radio. One of the early Debian Project Leaders,
Bruce Perens, also notably came to Debian for amateur radio purposes.
I passed the amateur radio exam in 1993,
when I was 14 years of age.
My first years of voluntary activities in amateur radio and free software
were during a time when I was legally a child. I didn't receive any
payment for some of those activities. I offered my time on the basis
that I was gaining skills and helping real communities.
Around the same time, while I was still legally a child, I came to
appreciate the fact that there are some adults who exploit talented and
precocious youngsters by trying to direct the work that is being undertaken
and failing to disclose or share financial benefits.
The Debian Project constitution was originally published on
10 September 1998,
some time later.
The trademark was only registered later on 21 December 1999
Looking at the Scientologie.org UDRP verdict, the panelists
gave some weight to those possessing a copyright interest that predates
the registration of a trademark or a copyright interest arising from
a situation that intersects with the history of the trademark.
Legitimate interest: the Debian license statement
Oddly enough, Debian documents and files in a Debian system refer
to the licenses of the individual packages being distributed. It
was hard to find an actual example of a copyright statement or
license for Debian itself as a collective work.
The
Debian Project constitution of 1998, referred to above,
encourages Software in the Public Interest, Inc to register a
trademark. It says nothing about copyright in the existing body of
work.
Here are the words from the original constitution:
Since Debian has no authority to hold money or property, any donations for the Debian Project must be made to SPI, which manages such affairs.
SPI have made the following undertakings:
1. SPI will hold money, trademarks and other tangible and intangible property and manage other affairs for purposes related to Debian.
So people can donate intangible property like copyright to SPI if they make a personal decision to do so. The constitution did not oblige us to make such donations/assignments.
This situation is well known in open source software development.
Some companies ask their contributors to sign a Contributor License Agreement
or an assignment granting all their rights to a central entity with
exclusive copyright.
Such an assignment can't take place through a majority vote, such an
assignment or transfer of rights to a single entity would require
the unanimous consent of every single author who ever contributed
to Debian. In the case of those authors who are deceased, we would
need to obtain consent from their estates.
Continuing the search for a Debian license,
on the ISO installation media, I found the file
isolinux/f10.txt which contains the very brief text:
COPYRIGHTS AND WARRANTIES
Debian GNU/Linux is Copyright (C) 1993-2016 Software in the Public Interest,
and others.
The Debian GNU/Linux system is freely redistributable. After installation,
the exact distribution terms for each package are described in the
corresponding file /usr/share/doc/<packagename>/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
It asserts that copyright is owned by Software in the Public Interest,
and others. Most of us are individual private volunteers and we
have never personally chosen to grant or assign our copyright interest
to Software in the Public Interest. I became curious about who put
this statement into the ISO image.
Debian is a collective work under the above US copyright law.
The work was initiated in 1993 by Ian Murdock in the United States.
In a Collective work (US), the authors (or co-authors) are selecting works
from third parties and arranging them into the final product, Debian,
a collective work. The decision making process that involves selecting
third party works and the decision making process that involves
arranging the third party works gives rise to the moral rights
of authorship in the Debian collective work.
The “authorship” in a collective work comes from the original selection, coordination, and arrangement of the independent works included in the collective work.
In the Debian world, the independent works are referred to as "upstream" source code. The authors of independent works are referred to as "upstream authors" or just "upstream".
The Debian maintainer guide describes the process of jointly selecting the independent works for inclusion in Debian. In particular, co-authors are required to create a public "Intent To Package" (ITP) report in the bug tracking system (BTS) so that other co-authors can discuss the merits of the selection decision. The requirement to engage in a shared discussion for every selection decision gives rise to joint authorship rights.
Moreover, the person who creates the package importing the independent work into Debian is required to create a manifest describing the inclusion of the independent upstream work. This manifest is the debian/control file. The Debian Policy Manual provides a list of fields in the debian/control files.
Some of these fields are dedicated to the coordination and the arrangement of the independent works within a Debian system.
Coordination of the independent contributions: the package dependency fields describe the relationships between packages that have to be installed together or which conflict with each other. In many cases, when a library package is a dependency for other packages, we have to ensure that the version of the library package in Debian is compatible with the dependent packages. We have a formal process of coordination in this case, the Transition process. Populating the dependency fields in the debian/control file and participating in a Transition process, either as the producer or the consumer of a dependency, are examples of coordination of the independent works from upstream authors.
Here are some examples where I personally engaged in these actions:
The fields Section and Priority impact the arrangement of the contributions from the perspective of the user. The person completing the values in these fields is engaged in the process of arrangement of the contributions in a collective work.
Therefore, the development of Debian includes features of
both a collective work and a work of joint authorship at the same time.
Moreover, due to processes such as library transitions, NMU and our
system of voting on certain decisions, any co-author may influence the
way that other co-authors are integrating the independent upstream works
into Debian. This cross-pollination of ideas and effort is a well known
feature of Debian. In other Linux distributions, the developers are
a little bit more siloed from each other.
Every two years, an official stable release of the Debian software
is released to the public. This process of releasing involves
declaring a version number that corresponds to a particular subset
of the contributions that are in a working state at the time of the
release. Even if a Debian Developer's contributions are obstructed
from inclusion in future releases, or if a Debian Developer commits suicide,
their work is still present in all the past releases that have been
published.
My own contributions are included in a number of these Debian releases
over the years.
This
report finds my name in changelogs and copyright files.
There are 21 pages of results.
Shooting themselves in the foot
To declare that the Debian Developers do not have authorship
rights at all would be incredibly de-motivating.
Future volunteers may be deterred from contributing their
intellectual property and their time.
Legitimate interests: the Debian family fallacy
Debian oligarchs repeatedly tell us that we are all a family.
Harry and Meghan were asked to stop using their
His/Her Royal Highness (HRH) styles.
Harry was banned from
wearing military uniform at the funeral of the late
Queen Elizabeth II. Yet they still have a legitimate interest
in using the family name, Windsor.
If Debian really is a family, and it certainly isn't an employer,
we can all use the family name even if we are not willing to live with
each other in the same castle.
Legitimate interests: the promise of recognition
The misfits behind the WIPO insults do not pay the rest of us anything
for our collaboration in creating the Debian software.
They told us that the only thing we get in return for our creations
is the recognition.
They are now using the debian.org web site and the trademark
to give people negative recognition. This is like bouncing a cheque.
In the circumstances, it seems entirely appropriate for me to follow
through on the promise of recognizing people. The misfits have provided
a list of the domains along with the dates that each domain name was
registered. On the list, the name debian.plus is the first
name registered. debian.plus was registered for the purpose
of delivering on the promise of positive recognition to the
authors and our work.
Debian promises recognition, I take the following quote from
the latest Debian law suit where they admit using the promise of recognition
to lure people into working for free:
64. ... un des avantages importants de travailler pour la communauté Debian est la valeur de sa réputation dans le domaine, à la fois professionellement et dans la communauté. ...
The motivations of the authors also are varied, but the coin that they get paid in is often recognition, acclaim in the peer group, or experience that can be traded in in the work place
you are recognized for your contributions ... Did you ever have a boss who takes credit for your work? Not in Debian.
In short, there is a big emphasis on working for recognition instead of a salary. They gave us the promise of recognition and that gives rise to a legitimate interest in using the trademark in domain names for web sites about our work.
Legitimate interests: promoting my creative efforts
The scientologie.org UDRP verdict makes reference to the
promotion of an author's work.
This point was also emphasized by the legal panel considering
previous Debian disputes. The panel wrote:
Unlike the circumstances in Religious Technology Center
v. Freie Zone E. V, supra the Respondent in the present case is not using
the disputed domain name to disseminate information about its
copyright work.
All the web sites that have been started using these domains
involve the promotion of my creative work in a Debian context.
Several of the domain names have been chosen in
recognition to my own work in specific areas of Debian. For example,
the domains debian.chat,
debian.finance and
debian.video have already been
started with information about my work on software relating to
financial software, chat software and video software, as well as
videos about my work.
Legitimate interest: EU whistleblower directive,
raising workplace health & safety concerns
With this authorization, any person who obtains a copy of the
software is entitled to redistribute it.
The DebianGNULinux.org
domain name was registered to do exactly that, to redistribute
copies of the Debian software. This activity has been authorized.
Remarkably, in one of their claims submitted to another tribunal,
the misfits explicitly describe a web site redistributing Debian
as an outrageous crime, despite the fact the DFSG and the license
statement referred to earlier explicitly authorize redistribution of
genuine copies of Debian GNU/Linux.
Such a flagrant violation of the principles in the DFSG appears
to be bad faith on the part of the complainant.
Legitimate interest: use of the logo is authorized
The page describes two versions of the logo, the open logo
and the restricted use logo.
The page gives a free-for-all license to use the open logo.
The logo I am using on pages about my Debian work is the open logo.
Here is the text of the authorization from the trademark holder:
The Debian Open Use Logo comes in two flavors, with and without “Debian” label.
The Debian Open Use Logo(s) are Copyright (c) 1999 Software in the Public Interest, Inc., and are released under the terms of the GNU Lesser General Public License, version 3 or any later version, or, at your option, of the Creative Commons Attribution-ShareAlike 3.0 Unported License.
Legitimate interest: use of Debian-themed web page style
The Debian web page style is used extensively on third party web sites
run by individual co-authors and volunteers.
At the bottom of every page on the main
www.debian.org
web site there is a link to a dedicated page about the licenses
(authorization) to re-use the theme and content of www.debian.org.
Since 25 January 2012, the new material can be redistributed and/or modified under the terms of the MIT (Expat) License or, at your option, of the GNU General Public License; either version 2 of the License, or (at your option) any later version (the latest version is usually available at https://www.gnu.org/licenses/gpl.html).
Work is in progress to make the older material compliant with the above licenses. Until then, please refer to the following terms of the Open Publication License.
This material may be distributed only subject to the terms and conditions set forth in the Open Publication License, Draft v1.0 or later (you can read our local copy, the latest version is usually available at http://www.opencontent.org/openpub/).
“Debian” and the Debian Logo are trademarks of Software in the Public Interest, Inc.
The complainant publishes the source code for the web site theme.
This makes it easy for anybody empowered by the above license to download
the theme and use it when creating their own site.
At the bottom of every page on Debian.org, they promote
the source code for the web site with a link text
"Web site source code is available".
The misfits have been making gossip against my family and I long before
I registered any Debian-related domain names.
Notably, they use the Debian trademark and the Debian.org web site
to add weight to their vendetta to humiliate volunteers and our families.
They censor, threaten and blackmail anybody who dares to challenge
their vendettas. "We are humiliating Bob this week, you can't talk to him
or you are next".
That is what it looks like when misfits blackmail other volunteers.
Therefore, to respond to the vendettas published on Debian.org
by operating similar web sites containing the name Debian
feels entirely reasonable and proportionate as a right-of-reply
by any co-author.
Bad faith: by the complainant, not me
For a UDRP case to be successful, in addition to proving that there is
similarity to the trademark and if the complainant somehow proves that there
is no legitimate interest whatsoever, the complainant must also prove that
there is bad faith in the use of the domain names.
In this case, I believe the test for legitimate interest has already
been satisfied and therefore, when legitimate interest exists, the panel
does not make any inquiry into whether there is bad faith on the part
of the domain name holder.
Under the UDRP Rule 15(e), it is also vital for the legal panel to consider
whether the complainant themselves is harassing the domain name owner or
acting in bad faith. In other
words, whether the complainant has deceived the panel,
whether a complaint has been brought for the purpose of
harassment or whether the complaint is part of a broader pattern
of harassment against the domain name holder.
Therefore, I simultaneously examine the attacks the complainant
is making against my family and I, demonstrating not only that they are
unjustified but also that by making these attacks, the Debian misfits
themselves are clearly engaging in harassment and bad faith behavior.
Bad faith: no communication before opening the WIPO UDRP procedure
The misfits did not make any attempt to contact me and propose
a solution to the conflict. They unilaterally opened a dispute through
the UDRP.
There have been many opportunities for them to communicate with me
like a human being. They talk about Debian being a "family" but
they pack together like gang rapists to pick off developers one
at a time and attack us.
They are bypassing any normal human communication because they
want to cause the maximum amount of stress. They want
WIPO to publish the name of my family in a negative context more than
they want any of those domains.
In such circumstances, they prove they are committing the act of
harassment under UDRP rule 15(e)
Bad faith: lawyers get the lifejackets, Abraham Raji gets none
In January 2023, I published a
picture of our crew rowing Head of the Yarra. The guy sitting
behind me won the award for Emergency Practitioner of the Year.
He is just the type of person you would want to have around if
somebody went missing in the water. But in all the years we did
rowing, I don't remember anybody going missing.
A few months after I published that photo and
Abraham Raji
disappeared and drowned on the DebConf day trip.
According to the
Wiki page for the day trip,
volunteers participated in a series of activities throughout the day.
To participate in the final activity, the kayak, the volunteers were
expected to pay an extra fee. People not paying the fee would be
left alone to swim like Abraham Raji.
In Australia, we all learn the basic rules of swimming. Never swim
alone is one of those rules. Swim in the marked swimming areas.
Debian people like to reinvent the wheel and find their own way
of doing things. The DebConf organizers are particularly bad at this.
People are constantly bike shedding about the costs of minor things.
They tell the foreigners from poor countries that they have to
pay their own visa fees. They expected the Indians to pay
the supplement for going in a kayak, which comes with a life jacket, or
be left alone.
But according to their own records, they paid over
$120,000 to lawyers to attack my family and I. Paying the
lawyers was more important than providing supervision or life jackets for
victims like Abraham Raji.
Given this vendetta has drained so much of the budget that somebody
was left without a lifejacket and he died, it is clear to me
that this vendetta is brought in bad faith and it violates UDRP rule 15(e).
Bad faith: attacking a volunteer at a time of grief, disrespect
for the sanctity of human life
The complainant admits they began attacking my family and I
in 2018 (evidence: screenshot of doxing messages from Chris Lamb
further below). This was a time when I lost two family members and it was
a disturbing time for my family and I for a range of reasons.
I told fellow collaborators that I couldn't fully commit to some
of my voluntary responsibilities at that time.
(email to Molly de Blanc)
At the same time, one of the issues causing controversy is the
appearance of a Debian suicide cluster or an open source software
suicide cluster. The attempt to minimize attention on individual
suicides also has the effect of minimizing discussion about whether
the combined body of deaths form a cluster. Public health authorities
define three or more suicides as a cluster. The
public health authorities advise that clusters need special attention
to avoid the risk of further deaths.
Moreover, given the way that the Debian deaths intersect with
my own family life, including the unexplained
death of Adrian von Bidder on the day of our wedding,
a possible suicide,
the grief and toxicity associated
with these phenomena have inevitably become intertwined.
This phenomena should be examined from an independent perspective,
with a focus on the issues and not trying to misdirect attention towards
a volunteer who expressed concerns about it. Forcing an individual
volunteer to write about such phenomena under the threat that WIPO
will denounce me is abhorrent.
Given that we already have this unexplained Debian death on the
very day of our wedding, which is a huge scar, how can they possibly be
imposing more scars upon my life with the continued burden of public
harassment on the Debian web site and through WIPO? It is too much and
it has been going on for too long.
Therefore, the bad faith is entirely on the part of those bullies
forcing the matter before WIPO.
Bad faith: psychological torture / cybertorture
In the role the community elected me to perform, I gave people
accurate assessments of the FSFE as an organization. The people
caught doing the wrong thing responded with personal attacks on my
family and on me as an individual.
It is entirely correct for us to scrutinize the functioning of a
group or organization like that. It is wrong for such groups to turn
on an individual volunteer.
Prof Nils Melzer, United Nations Special Rapporteur on Torture and
Other Cruel, Inhuman or Degrading Treatment or Punishment has published
a report on the practices of cybertorture and psychological torture.
An earlier blog post examines the phenomena in Debian.
The insults submitted by the misfits write about excluding
people. We saw similar tactics in the case of the
"hooded men" in Northern Ireland. The obsession with excluding
and isolating people, which comes up frequently in online discussions
between the enforcers, is truly evil.
The defamation and insults created by the Debian misfits focus on
a period when I lost two family members. By making repeated references
to that period in 2018 they are seeking to trigger and exploit feelings
of grief. This is the sort of deliberately cruel behavior envisaged
by the UN special rapporteur.
Given that the misfits used WIPO and the UDRP to transmit documents
targetting a period of grief, this is an example of a complaint brought for
the purposes of harassment in violation of UDRP rule 15(e).
Bad faith: intent to use the domains for vendettas
The misfits provided a copy of a previous UDRP censorship decree
for a domain they seized. After seizing the domain, the misfits
have not used the domain for any original purpose. They are only
using the domain to publish insults and attacks against my family and I.
Therefore, it would be reasonable to assume that any domains censored
by this new UDRP case will also be weaponized against me.
Given that they have already behaved like this before, with their
use of debian.community, it would be no surprise if they
continue that behavior with any other domains they steal. Therefore,
their intention is to harass me, as prohibited by UDRP rule 15(e).
Bad faith: voluntary work intertwined with our lives
The work we do as open source software developers intersects
with many other aspects of our lives.
For example, when we participate in other voluntary groups in
the real world, we often help them with their technology requirements.
The solutions we provide often involve Debian and other free software
products. When misfits start spreading rumors from Debian into social media
networks, this is harmful to other groups where we participate and
at the same time, it is harmful to our own personal lives,
the places where we go to socialize away from our computers,
the places where we go to exercize and so on.
This intrusion on multiple aspects of our lives, both professional
and personal, is not by accident, it has become a deliberate intention
of the rogue leadership figures who engage in publicly
humiliating volunteers.
Therefore, given the impact that public denouncing us has on our
lives, it is harassment and it violates UDRP rule 15(e)
Bad faith: suicide, stigma and tarnishing
WIPO panelists are asked to consider whether the content of the web
sites tarnishes a trademark. There is clearly a lot of stigma around
suicides. It is inevitable that some tarnishing may occur when
suicide is mentioned.
Nonetheless, the panel needs to consider whether tarnishing is the lesser
evil.
The factual revelations of a suicide cluster do run the risk of tarnishing
the Debian trademark, I am not going to dispute that.
Yet the panel can not automatically conclude that tarnishing is
done in bad faith. If the reason for publishing evidence related to a
suicide cluster is in the interest of public health and preventing more
suicides then it looks like tarnishing but it is NOT bad faith.
Given the nature of suicide, there is simply no way to publish
these public health concerns without the counter-accusations of
tarnishing.
In responding to the previous case of UDRP harassment by IBM Red Hat,
in relation to the domain name WeMakeFedora.org,
I made reference to the Holmes and Rahe Stress Scale.
The loss of a family member is one of the highest events on the scale,
between 63 and 100 points. Significant attacks on the business, career
or professional reputation are rated between 39 and 47. It is suggested
that when these events and scores combine, for example, through bad luck
or persistent harassment, overall scores over 300 are highly likely to
have an impact on health. In other words, there is a higher risk of
illness, accident and suicide for people subjected to stress of this
level.
The complainant is clearly aware of these arguments from the prior
WeMakeFedora.org case so their decision to embark upon
a copy-cat case and deliberately submit documents refering to 2018,
the specific time when I lost two family members, appears to be
a reckless and deliberate attempt to knowingly impose more pain on my family
and I. Therefore, it is clearly a violation of UDRP rule 15(e),
harassment and bad faith by those who initiated the procedure.
Bad faith: concealing risks to children
When IBM Red Hat submitted their case in the UDRP, they included as
evidence an example of content from the WeMakeFedora.org
web site. The example included five blog posts and one of those was
a blog that had originally been published by me and then automatically
syndicated by WeMakeFedora.org.
The blog that IBM Red Hat complained about and therefore wanted to
censor was the blog post
Google, FSFE & Child labor.
FSFE is a non-profit puppet organization jointly funded by Google,
IBM Red Hat and other large corporations.
There are a subset of Debian co-authors who are also associated with
FSFE.
As the community had elected me as the FSFE Fellowship representative
and as I had concurrently been a mentor and administrator in programs
like Google Summer of Code (GSoC) and Outreachy, I had an important
role to play documenting the risks to children.
At the same time these risks to children began appearing in the world
of open source software, the criminal procedure against Cardinal George
Pell had been unfolding in Australia. As it turns out, a family member,
some years younger than me, had been in the choir at the time that the
late Cardinal Pell was Archbishop of Melbourne.
I had personally been an officer of the National Union of Students
(Victorian state branch) in 1999. As far as I can tell, I was the most
senior student representative having contact with somebody in the choir
at the very
time that the late Cardinal was in charge. When I saw risks to children
around the open source software world, how could I not express concerns?
I had started doing voluntary work as a GSoC mentor in 2013. Therefore,
I had five years experience of these programs when I came across the
problems in Albania in the latter part of 2017. I used internal channels
to raise concerns about the risk to minors.
Complainants knew my concerns were based on long standing experience
and on personal exposure to these situations. While credible organizations
would have found a way to deal with these matters diplomatically, the
complainants are simultaneously trying to both censor me and discredit
anything I have to say about these risks.
The fact that IBM Red Hat cited the child labor blog in their UDRP
submission shows that is what they were trying to cover up. Their
UDRP complaint was ruled an act of bad faith.
The fact that I had both privately and publicly expressed concerns about
the risk to children and the timing of Debian's UDRP action coincides so
closely with IBM Red Hat makes me feel they are seeking to censor and
undermine exactly the same concerns about risks to children.
Looking at the way the FSFE's child labor program progressed,
we can see that when the program finished, FSFE obfuscated the
full names of the children who did the work. These children clearly
have a copyright interest in the work they created. In other fields
of endeavour we can see children receiving credit for their work
under their full name. For example, look at the Jackson Five,
where
Michael Jackson began performing under his real name from age five.
The French pop singer
Marina Kaye (a stage name) appeared under her
real name Marina Dalmas on France's Got Talent when she was thirteen years old.
Yet the children who wrote code for FSFE are not given credit under
their full names.
Only their first names were published.
The trial of Cardinal Pell never proved whether abuse took place.
What has been confirmed by medical evidence is that one member of the
choir began substance abuse at approximately fourteen years of age.
There are multiple possible explanations for the substance abuse. For
some of the boys, participation is a burden and they never sing again
after graduating from the school.
The choir was associated with the pressure of maintaining a
scholarship at one of Australia's most expensive schools. The FSFE
YH4F program involved the pressure of competing for a financial prize.
When somebody like me with exposure to both of these situations expresses
concerns, why are these organizations so desperate to cover it up?
The internal reports I submitted about harassment of women and
risks to minors in 2017 are contemporaneous evidence of what really
went on in proximity to the Outreachy funding in high risk countries
like Albania. I was often the only mentor to personally witness the
behavior of local men and women in these groups.
In 2013, when the Australian government sought to humiliate
Iranian women and migrants with a video, I loudly resigned my membership
of the party. This was nine years before the rest of the world took a
serious interest in the plight of Iranian women protesting against
a headscarf Code of Conduct. Even more telling, my written concerns
put the mistreatment of these women in the same category as the alleged
abuse in the Catholic church. The concerns were
captured by Crikey.
Given my personal involvement as a witness over many years, my track
record of being right about these things, sometimes well ahead of time
and the track record of organizations trying to silence people who raise
concerns about abuse, the attempts to discredit my testimony about these
matters in proximity to GSoC and Outreachy is itself the act of bad faith,
a violation of UDRP rule 15(e).
Bad faith: companies trying to keep the real abuse reports in-house
In the world of free and open source software, we have the unique
phenomena of corporate employees working side by side with
developers who work for competitors and also the unpaid volunteers.
After the commmunity elected me as the FSFE Fellowship representative
in 2017, I began to receive significantly more detail about wrongdoing
that goes on in the world of free and open source software. It is
understandably surprising and disturbing for some of the larger companies
to discover that these reports about their employees were going to an
external volunteer and not to their in-house human resources department.
It is a useful moment to compare this situation to how it worked
in the institutional abuse crisis. Australia's Royal Commission published
many of the internal documents from the institutions concerned.
One set of meeting minutes from the Archdiocese of Melbourne stands out.
The Personnel Advisory Board (PAB), a group of highly trusted clergy
who assist the Archbishop with the appointment of clergy to different
roles, has realized that their board is too big and they need to create
smaller sub-groups to handle the more sensitive cases.
Father X____ raised the question of how much is told to whom.
Father X____'s name appears frequently as somebody involved as an architect
of the cover-up. His parish web site notes that
he went into retirement in 2016. Coincidentally, that was
the very moment the Royal Commission was seeking answers from
Cardinal Pell.
Miraculously, Father X____ reappeared very briefly in 2023 to give
a sermon at the funeral of a relative in a tiny village that few people
would have heard of outside the state of Victoria. The following month,
three people from that obscure village died in a mysterious mushroom
poisoning that made headlines around the world.
Here is a snippet from the sermon, the man who moved pedophiles not
only from one parish to another but also from one institution to another.
He mentions a family connection with
a former superintendent of An Garda Siochána (the Irish police).
By moving known pedophiles around, Father X____ enabled more abuse
to take place and this resulted in more lives destroyed by overdoses
and suicides.
Those seeking to discredit a former community representative
are acting a lot like the institutions in the abuse crisis.
As the WIPO UDRP guidelines tell us, anything that tarnishes the
brand of Debian or the church has to be censored and covered up.
They are seeking to remove, censor and discredit me simply because people
told me things I wasn't supposed to know. They would have preferred
that some of these issues with women and children were only known
to a select group of people appointed by the companies, just
as the Personnel Advisory Board sought to limit knowledge of certain
matters to the smallest possible sub-committee of clergy.
While the move to keeping information in-house is understandable
and many companies even have an obligation to do so due to
the privacy rights of their employees, it is not acceptable that
they retrospectively punish me for my knowledge of these things. If
punishing me or discrediting me for that role is part of their objective,
they are the ones behaving in bad faith, violating UDRP rule 15(e).
Bad faith should not be alleged against an individual volunteer
Working in IT, our personal reputations for integrity are essential
for us to feed ourselves and support those who depend on us.
A bad faith finding is likely to cause significant harm to a volunteer's
ability to seek employment, obtain credit and enter into insurance contracts.
There have been complaints that WIPO panels have been making bad faith
findings in cases that are ultimately about political speech rather than
integrity of the publisher. This is very dangerous for personal victims
of such findings and those who depend on such victims.
Moreover, using the bad faith verdict arbitrarily cheapens the
meaning of the term bad faith.
It seems incredulous that a vindictive trademark owner can pay
$1,500 to WIPO to make such an attack on a volunteer that will
destroy that person's future and cause significant harm to those
around them.
It is even more abhorrent that they can do such a thing to somebody
who has contributed decades of voluntary service and to somebody suffering
the loss of two family members at a time of grief.
Scrutiny should be turned around on those organizations who are
exploiting our work and then menacing volunteers with the
total loss of our livelihoods.
Bad faith can't be alleged when following a precedent
If a domain name holder has been motivated to register and
use a particular domain name based on the logic of previous UDRP
decisions, it would be very unreasonable to find the domain name
holder is acting in bad faith.
There was widespread discussion of the scientologie.org
verdict last time there were disputes about Debian domain names in 2022.
Based on those discussions and my new awareness of the
logic behind the scientologie.org verdict, I felt that I had
very reasonable grounds to register some Debian domains for the
purpose of promoting my work in Debian and for promoting Debian,
our collective work, as a whole.
Given that I was motivated by the precedent from another WIPO
panel and there are good reasons for me to feel that I have
legitimate interests on the same grounds, as somebody with a copyright
interest, it is entirely unreasonable to accuse me of bad faith.
Looking at the list of open disputes in the
WIPO UDRP case search,
I can see that the list of domain names in dispute only has one
thing in common: they are all owned by one person, me.
It is clear they are not concerned about the content, they are
concerned with attacking the person, me.
Moreover, this ad hominem attack behavior has started before the
registration of the domains and before the complaint. For example,
the defamation statement submitted by the complainant is another
example of an ad hominem attack. The statement is dated 2021,
before all but one of these domains were registered. It shows that the
complainant has a history of making ad hominem attacks with
an intention to harm my family and I.
An ad hominem use of the UDRP process is therefore harassment
by the complainant and a violation of UDRP rule 15(e).
Bad faith: complainant seeking revenge for whistleblowing about bad
faith
Insults submitted by the complainant as evidence show they started
harassing my family and I in 2018.
If we drill down, we find they started this harassment in September
of that year.
In April 2017, the FSFE members elected me as their Fellowship
representative. There is a significant overlap between members of
the FSFE (approximatley 1532 people at the time of the election)
and co-authors of the Debian software.
If you hire an engineer to inspect a used car, you would hope that
they would be able to verify basic things like the authenticity of the
serial number (VIN) on the vehicle chassis. As the elected Fellowship
representative, I had an obligation to report the FSFE was not what
it claims to be.
The money that volunteers and private individuals have contributed
to FSFE over the years is far more than the value of most used
cars. Therefore, in the case of FSFE, there is both evidence
of bad faith and there is quantitative evidence,
the financial reports,
showing us the impact of that bad faith.
The attacks against my family commenced immediately after I published
the evidence of bad faith by FSFE. The email was sent to the LibrePlanet
list on 11 September 2018 and the attacks began about one week
later, as shown by the date of the email from Chris Lamb below
on 20 September 2018.
The attacks against my family and I are a predecessor of this
harassment through the UDRP. It has been a continuous pattern of
harassment over six years now. It appears that this harassment,
of which the UDRP insults are just the latest instalment, is part
of an overall reprisal for the reports I gave the community in
my capacity as the Fellowship representative.
Using the UDRP to insult and harass a volunteer community representative
as a reprisal for performing their duties is clearly an act of
harassment and bad faith as anticipated by UDRP rule 15(e).
Evidence: email from Mirko Bohm: I would like to thank you for your contributions to FSFE and for your commitment not to shy away from asking the difficult questions and calling out the need for change where it exists.
Bad faith: complainant reneges on their own Diversity Statement
The pack adopted the Debian Diversity Statement by a General Resolution in which all the co-authors were invited to vote.
The Diversity Statement begins with the line:
The Debian Project welcomes and encourages participation by everyone.
The insults that they submitted with the complaint, the defamation
statement created by Donald Norwood in the Debian Press Team, contradicts
their own Diversity Statement which was adopted by a General Resolution.
Such a contradiction demonstrates a significant lack of integrity
and their defamation statement should not be taken seriously.
I informed people that I had resigned from some of my voluntary roles
at a time when I lost two family members. Therefore, their behavior
towards my family and I is not just a plain vanilla violation of the
diversity statement, it is an aggravated violation. It is bad faith.
Bad faith: the complainant is gaslighting about authorship and membership
The complainant appears to pivot back and forth between concepts from
copyright law and from the law of associations.
Consider the case when somebody begins contributing to Debian.
There is no such thing as a "New member" process. Rather, it has
historically been called the "New maintainer" process. We can see that
clearly in the
name of the
debian-newmaint mailing list.
The word "maintainer" primarily implies somebody is doing creative work to
select, coordinate and arrange more independent works into Debian.
Then we have the guide for the
New Member process, which was previously known as the New
Maintainer process. In step 3, explained in that page, the new contributors
are asked to agree to the Debian Social Contract,
the Debian Free Software Guidelines and the
Debian Machine Usage Policy. The former is ultimately about our relation
as authors, not as members and the terms under which we license our
work to the rest of the world.
The new maintainer/member guide doesn't ask people to ratify
their adherence to the constitution. The notion of joining an association,
whether it is incorporated or not, is inseparable from consenting to
be governed by and uphold the association's constitution. The
only people who ever ratified the constitution were
86 co-authors
in 1998 (23% of the developers at that time) who wanted to have
a constitution.
Somebody who did not ask to be a member can't be expelled.
Somebody who is not an employee can't be demoted or sacked.
Yet we have seen some of the leadership figures insist on having
these powers over a
series of victims. The title Debian Project Leader
implies just that: to lead, not to give orders.
The insinuation that concepts of expulsions and demotions can
be applied to co-authors is an example of gaslighting.
Copyright law is very clear: co-authors of a work are
equal. Notions of expulsions and demotions violate
the principle of being equal.
The fact that they are knowingly and deliberately trying to obfuscate
our moral rights as co-authors, giving us nothing in exchange
for the status they are taking away, is an aggravating factor
that justifies the finding of harassment and bad faith against
the complainant.
Bad faith: use of an administrative process to extinguish the moral rights and recognition of co authors
The paper notes that the Nazis used administrative law to
frustrate the rights of authors, just as misfits are using a WIPO
administrative process to harass and intimidate a Debian co-author.
Quoting the journal article:
Despite the fact that written IP legislation in Nazi Germany
did not include specific exclusions for Jewish applicants and authors,
in practice, they were excluded by administrative measures alone
rather than legal ordinances.
The misfits frequently use the same language, the word "exclude" comes
up again and again. Harassment, UDRP rule 15(e)
Bad faith: Debian Trademark Policy never ratified
Debian co-authors have never been asked to individually ratify the Debian
Trademark Policy or any similar regulations.
A trademark policy published unilaterally by the trademark owner
can give people authorizations above and
beyond fair use and legitimate interest. On the other hand,
such a policy can not unilaterally erode the default rights to
fair use and legitimate interest.
Hypothetically, the complainant could ask co-authors to
sign some agreement waiving our fair use rights. This may
happen in the context of employment, where those who receive a salary
agree to forego other rights.
Debianists do not pay us a salary and they did not ask us to
individually ratify any agreement waiving our fair use rights.
They have
never tried to do this. The only agreement they ever asked each and
every one of us to individually ratify is our adherence to the
Debian Machine Usage Policy and to the Debian Social Contract.
Therefore, in my role as a co-author, I am not bound by
any restrictions unilaterally imposed upon us by
the Debian Trademark Policy and only the normal rules of
fair use and legitimate interest can be considered in this dispute.
Moreover, it is bad faith by the complainant to simultaneously insist that
they can expel somebody, which is really a nonsense concept in terms
of joint authorship rights, as such rights can't be extinguished
and then insist that the people supposedly expelled will still
remain bound by rules from above that only apply in the context of
being a member of their clique.
Bad faith: complainant reneges on existing authorizations
As noted in the statements on legitimate interest, the
complainant has clearly authorized many of the things they complained
about.
The Debian Social Contract, which states "We will not hide problems",
authorizes discussion of controversial technical, social and ethical
topics. In fact, it is more than an authorization, it encourages
such discussions and publications. Therefore, their complaining
about what is published on these web sites is itself an act of bad faith.
They authorized use of the logo, as discussed, so their complaining
about use of the logo is itself bad faith.
They put the web site theme and content under the open source licenses,
as discussed above, so their complaining about sites with a similar
appearance is itself bad faith.
Overall, for their claim of bad faith to supercede these authorizations,
they would have to demonstrate some extraordinary acts of wrongdoing,
for example, to show that a web site was using the trademark, domain
name and logo to distribute a virus. They provide no evidence of
such wrongdoing.
Bad faith: the complainant's evidence
They submit many boilerplate documents containing copies of
the domain and trademark registrations. On top of that, they
only submit three other documents.
One of those is the copy of a judgment from a previous Debian
dispute. The judgment expresses concern about some specific images on another
web site. The complaint does not provide any examples of those
images or any similar content on any of my own Debian web sites.
Therefore, this judgment can't be extrapolated to content on my
own web sites.
They provide a copy of biographical information about me from
my company web site. This is not published on one of the domains
in dispute so it is not relevant. By providing this, they are insulting
me. Looking at the very first archived copy of an email from
the debian-project mailing list in 1994, we
find that Debian co-authors are using the term
Debian Developer four years before there was a trademark. That is
four years before the Debian Project constitution. The term
Debian Developer is completely valid
for somebody who has done significant creative work over many
decades. In plain English, the term Debian Developer can mean
three things: somebody who possesses the skill of creating
Debian software, somebody who has an authorship interest in
the Debian software and thirdly, but lastly, somebody who is
a member of the clique. Copyright law does not require somebody
to be a member of the clique. I never joined the Debian Project
Unincorporated Association, I have always used the term
Debian Developer first and foremost to describe myself as an author with
moral rights in the creative work. Given that they have taken
this text from a web site that is not even part of the dispute,
I feel the legal panel would be best to avoid getting involved
in this aspect of the dispute.
The third document they provide is a defamation they created
themselves. They are clearly hoping to have WIPO republish
insults and defamation to cause some sort of harm to my
ability to work and feed myself.
They allege that there was some issue of harassment
but do not provide any details. They claim it was in the year
2018, a period when I lost two family members. Their insistence
on twisting a knife in my back at such a time only proves
bad faith on their part.
In various ways, we can see that the document they submitted
is a fraud that has the possibility of deceiving the WIPO
legal panel.
For starters, the harassment began in 2017. Even
the year specified in their evidence is wrong. Therefore,
the evidence they are submitting is a deliberate deception that
tries to invert the story.
Here is the internal report about the harassment. The date is 12
October 2017 so the misfits are clearly lying to the WIPO
legal panel. I have redacted the section that identifies
underage victims.
There you have it. The most senior student representative to have
had contact with a member of the choir in the era of Cardinal Pell has
subsequently arrived in Albania and correctly and discretely raised the
alarm about pimps and pedophiles using funds from Mozilla, IBM Red Hat
and other tech companies to bait their child victims and young women.
It is creepy how the complainants deception about the dates and details
mirrors the case of the
Swiss JuristGate scandal. The
Swiss financial regulator, FINMA, has published a summary
of their decision to shut the rogue firm. In the summary
of the decision, not only does FINMA redact the names of those
responsible for ripping off the customers, FINMA even redacts the dates.
One of the reasons FINMA is redacting the dates is to hide how long
the regulator and the bar association really knew about the scandal.
The hidden dates are examined in more detail in my first
blog post about Juristgate. Here is a screenshot from the FINMA
document showing where the year is obfuscated / redacted:
The FSFE
Fellowship elected me as a community representative in April 2017.
Shortly after that, women in Albania confided in me about the incidents
of harassment. I traveled there again to help organize a MiniDebConf
and Fedora Women's day and in the process, I became a witness to
acts of harassment and a serious possibility of underage abuse.
All of this clearly began in 2017 but the defamation created by
Debian seeks to obfuscate the year and the source of the harassment.
They completely fail to thank me for the effort I made supporting
these women. This was an effort above and beyond what had
been anticipated when I volunteered to speak at the conference
in Albania.
At the time, I had confided in the women that I was watching
these matters very carefully because one of my cousins, who is much
younger than me, had been in the St Patrick's cathedral choir
during the time Cardinal George Pell was Archbishop of Melbourne.
The Pell case was one of the most high profile allegations of abuse
in the Catholic Church. The Royal Commission notes in their
report that of 15,000 victims who contacted them,
the Catholic Church was implicated in far more cases than all the other
religions combined.
In the meantime, Carla had also written about her eating disorder
on her web site. Research estimates that at least thirty percent
of women with these conditions have been victims of harassment or
abuse in childhood.
Various people appeared to resent the fact that women had given
evidence about an (IBM Red Hat) Fedora Ambassador and Mozilla
Tech Speaker to an independent, elected community representative
who was not under any obligation of confidentially to the companies
funding the Albanian groups. In other words, these companies
would have prefered to see the women reporting scandals through
internal company channels.
Shortly after I received this information from women, the FSFE
revised their constitution to
remove their annual elections and
ensure there would never be any other community representative again.
The complete removal of the election and the representative position
proves that this wasn't about any failing on my own part, this was
about the companies behind FSFE wanting to ensure that complaints
about their people wouldn't reach any independent outsider who
might be elected next.
At the end of the process, Mozilla produced a report about the
harassment. I have never been given a copy of the report and
the complainant has not submitted the report either. I don't
feel the complaint should be taken seriously at all unless all
parties, including the legal panel, are granted access to all these
original, contemporaneous documents about the origins of the
harassment and my support for the victims.
Meanwhile, at the very same time as the Cardinal Pell trial
was progressing in Australia, family and friends were shocked to
see mysterious references to abuse circulated on social media.
I don't even have any social media accounts myself so I only
started hearing about these character assassination plots
from witnesses who saw the smears. Cardinal Pell was convicted in December
2018 and a few weeks later, in January 2019, Joerg Jaspert of the
Debian Account Managers team put
mysterious references to abuse in one of our
Debian source code repositories.
One of the findings from the Royal Commission states that
abuse survivors who came forward took an average of 23.9 years to talk about
what happened to them.
Having attended a Catholic school in the same neighborhood and
having multiple connections with fellow alumni and the diocese, it
would not be a surprise for me if any one of the people I know
might reveal themselves to be connected with the scandal at some
point in the future.
Moreover, two of my cousins passed away far too young.
It is so shocking for me to see how these dirty men are playing these
games with the subject of abuse.
At the time that Joerg Jaspert started making these privacy
violations, he was on the school council at Dalbergschule in Fulda, Germany.
Local magazines published a photo of him in a Debian t-shirt
with other parents Claudia Beck and Ina Riechert.
How can the other parents and staff trust this dirty man with
any sensitive topics when he runs around spreading gossip about abuse
in the debian-private world?
Given that background, I find it abhorrent that these silly
people claim to be victims of abuse when what really happened
is they got caught doing the wrong thing. By claiming to be
victims of harassment and abuse, by hijacking and distorting
the language of sexual misconduct they are asking us to exhibit the same
sympathy for long-distance peeping toms at Google as we would for those
15,000 child victims.
Here is another example of Debianists pretending to be
part of the sexual crimes detective unit and circulating
gossip as if it was truth. The email is written by Russell Coker, a
Debian Developer in Australia, half way around the world from
where the rumors started in Berlin. How could he write such
forceful words about Dr Appelbaum when it is something he had no way to see?
This shows how Debianists use their titles and their trademark
to make stuff up and then give weight to defamation.
This type of rogue behavior makes it even harder
for the community to know when real victims take the difficult step
of coming forward with real reports of abuse.
Bad faith: deliberately conflating different types of harassment and abuse
The complainant frequently raises concerns about "harassment"
and "abuse" whenever somebody asks a question they don't want to reply
to.
Yet it doesn't stop there.
Not only do they claim to be victims of "harassment" and "abuse",
they deliberately seek to conflate different meanings of these words.
It works a bit like the game of Chinese Whispers.
The classic example was the lynching of Dr Jacob Appelbaum.
One person posted messages about "harassment". Somebody else who wasn't
actually there extrapolated that into "sexual harassment". Then another
person who was all the other way over the other side of the world in
Australia forcefully writes that it was a "rape".
The word "abuse" is used in much the same way. Somebody asks
a question about the bank account. The question is disparaged as
an unqualified example of "abuse". Later, somebody adds a prefix,
people mention "sexual abuse". But there is nothing sexual about
asking why somebody's girlfriend got paid to do work that other
volunteers do for free. We saw them using this word game in
relation to Prof Eben Moglen recently.
Not only are they trying to defame the person asking a serious
question but we also have to remember that when people try to
portray themselves as victims of "abuse", they are siphoning off a little bit
of credibility from the real victims, like those incredibly young boys
and girls who made complaints about institutional abuse. The pretend
victims and their antics dilute the credibility of the real victims.
Most healthy people are turned off by discussions like this. Yet
there is a subculture around Debian, a subgroup of volunteers who appear
to take some voyeuristic interest in making these word games with references
to abuse, the type of thing we see in the blog post by Matthew Garrett.
Just how did Garrett become an expert on abuse?
These comments about the phenomena may appear quite strong and
defamatory at first glance but the evidence is already public. Have
a look at the controversy about the package with the name "weboob".
According to reports, the source code is laced with crude references
to women. The package was
discussed on debian-private. Quite a few Debian men,
like Axel Beckert, a system administrator at the ETH Zurich university,
defended the package during his working hours.
Subject: Re: weboob package
Date: Fri, 13 Jul 2018 14:29:58 +0200
From: Axel Beckert <abe@debian.org>
Organization: The Debian Project
To: debian-private@lists.debian.org
Hi,
Jonathan Dowland wrote:
> Yesterday I stumbled across the "weboob" package for the first time,
> which includes a slew of binaries with names similar to the following:
[...]
So what? I don't see any problem with that. (And I don't see why
there's a thread on debian-private about it.)
Regards, Axel
--
,''`. | Axel Beckert <abe@debian.org>, https://people.debian.org/~abe/
: :' : | Debian Develoober, ftp.ch.debian.org Admin
`. `' | 4096R: 2517 B724 C5F6 CA99 5329 6E61 2FF9 CD59 6126 16B5
`- | 1024D: F067 EA27 26B9 C3FC 1486 202E C09E 1D89 9593 0EDE
Bad faith: timing of harassment
In each case, we can see that one of the Debian oligarchs has
engaged in some form of behavior that involves bullying or harassing
a volunteer and the disclosures about bullying have only happened
subsequent to that.
The vendettas began in September 2018. The complainant has submitted
their case of debian.community and we can see that the domain
name debian.community was only registered in October 2019,
more than 13 months after the Debian Project Leader started spreading
gossip about multiple volunteers.
In April 2021, I
incorporated a new company to promote
my work. In November 2021, the misfits began distributing their
defamation statement about my family and I as a reprisal. It appears
the misfits are jealous that I could start my own company and they wanted to
destroy it. In Australia, we call this the
Tall Poppy Syndrome.
In June 2021, one of the women was caught trying to start rumors about me
having a relationship with a female intern. The same woman was caught
again trying to start rumors in the same chat channel in July 2022.
In March 2023, I created a web site
Outreachy.Dating with proof that the rumors are false.
I did not spontaneously decide to go and create the
Outreachy.Dating web site. The
site only came into existence as a right of reply to the pre-existing
campaign of gossip against my interns, my family and I.
As already described in a previous section, when we agreed to
create Debian together, we agreed to uphold the Debian Social Contract,
which includes the commitment 3. We won't hide problems.
In 2018 and 2019, oligarchs started hiding the blogs of some co-authors.
The same phenomena occurred in the Fedora Linux community. I have
only had to register domain names like
Debian.News and
WeMakeFedora.org in response to the censorship of some blogs.
I did not just wake up one day and spontaneously decide to create
these domain names, I was motivated to do so because the censors
violated our existing rules of engagement, the Debian Social Contract
and the Fedora Foundations.
Bad faith: Debian's violent history of intolerance
Despite all the grand statements about the Code of Conduct, Respect
and Diversity, the Debian people are highly intolerant.
It has always been this way and there is plenty of evidence.
Consider 2006, the violent expulsion of Ted Walther from DebConf6 dinner
in Mexico. Somebody started a rumor that his dinner guest was a prostitute.
Nobody checked the facts. People physically pushed him out the door and
nearly threw him down the steps.
Instead of spending $120,000 on lawyers, they could have simply
apologized to my family for violating our privacy. But they are paying
all this money to rewrite history. They are paying the lawers all this money
to insist that the petty little word choice issues that their small minds are
preoccupied with are more significant than things like the death of
my father.
Bad faith: blackmailing people to disclose personal and private information
Whenever people come across the Debian smearing campaign through
social media and they ask me about the rumors of harassment and abuse,
the first things that come to mind are those cases that arose at
the time. The poor behavior I witnessed towards women from Albania,
Carla's eating disorder and the prosecution of Cardinal George Pell.
Other volunteers have made similar complaints about being blackmailed
to make public statements and disclose things about themselves.
Kuhn: As such, I'm outing myself here first (primarily) to disarm his ability to use what he knows about my sexual orientation against me.
In 2019, we saw that Dr Norbert Preining was blackmailed to
write a self-deprecating forced confession on a public mailing list.
When I saw that Dr Preining and I had been subject to similar
blackmail tactics, I felt that I was being expected to make
a similar public statement about matters that belong in private.
In the case of Bradley Kuhn, his disclosures relate to himself.
In my own case, in all cases of harassment and abuse where I have
been a witness, it is unthinkable that I should be forced by these
rumors to make disclosures about other people.
Therefore, when I published the Mozilla examples above, I partially
redacted them to avoid revealing the names of underage open source
software victims.
Nonetheless, I didn't voluntarily choose to publish responses
to gossip about abuse. They are using the WIPO UDRP to blackmail
me to publish comments about abuse cases. Therefore, they
are violating UDRP rule 15(e).
Bad faith: destroying our portfolio of work
In some industries, it is common for practitioners to carry
a portfolio of their work. For example, photographers, architects
and similar professionals often rely on such a portfolio to show
potential clients what they are capable of.
In computing, prospective employers and clients look at the
portfolio of our work in Debian and other free software projects.
Replacing that portfolio with insults and defamation is akin to setting the
portfolio on fire.
Once again, this appears to be the intention of the misfits behind
the complaint. By publishing attacks on my family and demanding
a verdict of bad faith, they are trying to further undermine the credit
I deserve for decades of work involving free and open source software.
It is harassment in violation of UDRP Rule 15(e).
Bad faith: how many Debian Developers really committed suicide?
There are 972 Debian Developers listed with the status
"Debian Developer, uploading". These are people considered to be active.
When people resign/retire, their status is changed to "Emeritus".
There are 449 Debian Developers with status Emeritus.
The status "Removed" is distinct from the status "Emeritus".
There are 272 Debian Developers with status "Removed". This list
includes people who have died, it includes victims who have been
disappeared and it includes people who have failed to respond
to any attempts to communicate. Some of these people may have been
participating under a fake identity. Some of them may have become
fed up with the politics and walked away without saying goodbye.
Some of these 272 people that we can't account for may have joined
the suicide cluster.
With or without a note, in this list of 272 people "Removed",
there will be many more we don't know about because their families
would never think to tell us.
How many of these 272 vanished after some secret humiliation on
the debian-private mailing list?
How many bloggers have committed suicide after WIPO denounced
them with accusations of bad faith?
Bad faith: deceiving the previous WIPO panel
The misfits have clearly deceived the previous WIPO panel on certain
issues. One of those issues is their claim that Albanian women
paid to travel to Brazil were junior female developers.
I was a mentor and administrator in both the Google Summer of
Code and Outreachy programs over a number of years from 2013 to 2018.
In that role, I interacted with many of the prospective interns,
both male and female.
I was involved in creating tasks that we asked the applicants to
perform to test their skills and demonstrate their motivation
during the selection process
for these internships. I observed the effort that each applicant made,
whether they were male or female.
There were definitely women who did a very high standard of work.
However, there were other women who did not do any software development
and we can see now in hindsight that some of those women still haven't
done any software development despite hanging around the open source
communities for almost a decade. Therefore, the claim that every woman
was a junior female developer was not true. Some women
were junior female developers, the rest we could not refer to with
the term developer.
We can see that the panel was deceived about the origins of
references to branding in the nether regions. This controversy, which
was mentioned in the panel's finding against another domain, is
rooted in the manner in which the misfits created rogue commits in
source code repositories on the anniversary of our wedding.
Specifically, we completed a civil wedding on 23 September 2010
and then we completed the religious ceremony a few months later
on 17 April 2011.
Here is the civil wedding certificate:
Here we can see the rogue commit in the Debian keyring repository,
on the date of the civil wedding, overlaid with the photo of genital
branding from NXIVM.
Given the way this extreme harassment simultaneously intrudes
on both my professional life and my family life, I find these
images even more horrific than they were for the WIPO panel.
Nonetheless, the images of genital branding are as relevant
as they are horrific when you consider the deliberate way these
misfits impose on our lives and our reputations.
Here is the date of the religious ceremony on my wedding ring,
alongside the tombstone of Adrian von Bidder, secretary of Debian.ch
who died in what appears to be a possible suicide on exactly the same day,
17 April 2011:
What an incredibly toxic culture the Debian misfits are trying to hide
with this WIPO UDRP vendetta.
The misfits have made multiple intrusions in the lives of volunteers.
While the scars are not identical, the mentality behind those scars is
much the same. In both Debian and NXIVM, some of the people feel they
have a sense of entitlement to impose upon all aspects of our lives and
our future, whether it is through branding, through gossip or through
demanding that WIPO denounces individual volunteers.
Bad faith: using WIPO and an Albanian gangmaster to defame me
I previously documented how I was a witness to acts of
harassment and the risks to underage participants by two
Albanian men. I attached the emails showing how this was
raised through internal channels at Mozilla.
When Chris Lamb decided to attack me on our wedding anniversary,
he actually used Elio Qoshi, the Albanian bringing a sixteen year old
girlfriend to tech conferences, to distribute the messages about
the vendetta.
At the time, I was with one of the victims. Women who had worked
with me personally had been surprised to see Lamb colluding with
these Albanian gangmasters. I took a photo of the message that
the Albanian forwarded from Lamb to the phones of female victims:
It is an extraordinary example of corruption. When I saw
Chris Lamb colluding with Elio Qoshi to denounce me at such a
painful time for my family, I couldn't help thinking of men like
Jimmy Saville and Rolf Harris collaborating in their
crimes.
Chris Lamb: You are well-aware that I
have been nothing but scrupulous and gentlemanly with regards to your
personal privacy and thus ...
The dishonesty of these misfits is as extraordinary as the
intrusion into the family lives of volunteers.
As Debian is an operating system, it is relied upon as the foundation
for so many other things that people do with their computers both
in industry and in private. In other words, people put a lot of trust
in the operating system but we can't trust the people making it.
Here we have caught the then leader of Debian using a common
garden variety Albanian pimp to spread rumors about a long standing
volunteer and also publicly lying about the matter.
Now these dirty little men aspire to exploiting a WIPO panel
in the same way they used this Albanian gangmaster to denounce
my family and I on the anniversary of our wedding. As mentioned
earlier, the deadline set by WIPO was Carla's birthday.
For a while ceb and I have wanted to contribute directly to green energy provision. This isn’t really possible in the mainstream consumer electricy market.
Mainstream electricity suppliers’ “100% green energy” tariffs are pure greenwashing. In a capitalist boondoogle, they basically “divvy up” the electricity so that customers on the (typically more expensive) “green” tariff “get” the green electricity, and the other customers “get” whatever is left. (Of course the electricity is actually all mixed up by the National Grid.) There are fewer people signed up for these tariffs than there is green power generated, so this basically means signing up for a “green” tariff has no effect whatsoever, other than giving evil people more money.
About a year ago we heard about Ripple. The structure is a little complicated, but the basic upshot is:
Ripple promote and manage renewable energy schemes. The schemes themselves are each an individual company; the company is largely owned by a co-operative. The co-op is owned by consumers of electricity in the UK., To stop the co-operative being an purely financial investment scheme, shares ownership is limited according to your electricity usage. The electricity is be sold on the open market, and the profits are used to offset members’ electricity bills. (One gotcha from all of this is that for this to work your electricity billing provider has to be signed up with Ripple, but ours, Octopus, is.)
It seemed to us that this was a way for us to directly cause (and pay for!) the actual generation of green electricity.
So, we bought shares in one these co-operatives: we are co-owners of the Derril Water Solar Farm. We signed up for the maximum: funding generating capacity corresponding to 120% of our current electricity usage. We paid a little over £5000 for our shares.
The UK has a renewable energy subsidy scheme, which goes by the name of Contracts for Difference. The idea is that a renewable energy generation company bids in advance, saying that they’ll sell their electricity at Y price, for the duration of the contract (15 years in the current round). The lowest bids win. All the electricity from the participating infrastructure is sold on the open market, but if the market price is low the government makes up the difference, and if the price is high, the government takes the winnings.
This is supposedly good for giving a stable investment environment, since the price the developer is going to get now doesn’t depends on the electricity market over the next 15 years. The CfD system is supposed to encourage development, so you can only apply before you’ve commissioned your generation infrastructure.
Ripple recently invited us to agree that the Derril Water co-operative should bid in the current round of CfDs.
If this goes ahead, and we are one of the auction’s winners, the result would be that, instead of selling our electricity at the market price, we’ll sell it at the fixed CfD price.
This would mean that our return on our investment (which show up as savings on our electricity bills) would be decoupled from market electricity prices, and be much more predictable.
They can’t tell us the price they’d want to bid at, and future electricity prices are rather hard to predict, but it’s clear from the accompanying projections that they think we’d be better off on average with a CfD.
The documentation is very full of financial projections and graphs; other factors aren’t really discussed in any detail.
The rules of the co-op didn’t require them to hold a vote, but very sensibly, for such a fundamental change in the model, they decided to treat it roughly the same way as for a rules change: they’re hoping to get 75% Yes votes.
The reason we’re in this co-op at all is because we want to directly fund renewable electricity.
Participating in the CfD auction would involve us competing with capitalist energy companies for government subsidies. Subsidies which are supposed to encourage the provision of green electricity.
It seems to us that participating in this auction would remove most of the difference between what we hoped to do by investing in Derril Water, and just participating in the normal consumer electricity market.
In particular, if we do win in the auction, that’s probably directly removing the funding and investment support model for other, market-investor-funded, projects.
In other words, our buying into Derril Water ceases to be an additional green energy project, changing (in its minor way) the UK’s electricity mix. It becomes a financial transaction much more tenously connected (if connected at all) to helping mitigate the climate emergency.
Now that we are back from our six month period in Argentina, we
decided to adopt a kitten, to bring more diversity into our
lives. Perhaps this little girl will teach us to think outside the
box!
Yesterday we witnessed a solar eclipse — Mexico City was not in the
totality range (we reached ~80%), but it was a great experience to go
with the kids. A couple dozen thousand people gathered for a massive
picnic in las islas, the main area inside our university campus.
Afterwards, we went briefly back home, then crossed the city to fetch
the little kitten. Of course, the kids were unanimous: Her name is
Eclipse.
Those of you who haven’t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the disclosure of what was, at the time, a fairly earth-shattering revelation: that for about 18 months, the Debian OpenSSL package was generating entirely predictable private keys.
The recent xz-stential threat (thanks to @nixCraft for making me aware of that one), has got me thinking about my own serendipitous interaction with a major vulnerability.
Given that the statute of limitations has (probably) run out, I thought I’d share it as a tale of how “huh, that’s weird” can be a powerful threat-hunting tool – but only if you’ve got the time to keep pulling at the thread.
Prelude to an Adventure
Our story begins back in March 2008.
I was working at Engine Yard (EY), a now largely-forgotten Rails-focused hosting company, which pioneered several advances in Rails application deployment.
Probably EY’s greatest claim to lasting fame is that they helped launch a little code hosting platform you might have heard of, by providing them free infrastructure when they were little more than a glimmer in the Internet’s eye.
I am, of course, talking about everyone’s favourite Microsoft product: GitHub.
Since GitHub was in the right place, at the right time, with a compelling product offering, they quickly started to gain traction, and grow their userbase.
With growth comes challenges, amongst them the one we’re focusing on today: SSH login times.
Then, as now, GitHub provided SSH access to the git repos they hosted, by SSHing to git@github.com with publickey authentication.
They were using the standard way that everyone manages SSH keys: the ~/.ssh/authorized_keys file, and that became a problem as the number of keys started to grow.
The way that SSH uses this file is that, when a user connects and asks for publickey authentication, SSH opens the ~/.ssh/authorized_keys file and scans all of the keys listed in it, looking for a key which matches the key that the user presented.
This linear search is normally not a huge problem, because nobody in their right mind puts more than a few keys in their ~/.ssh/authorized_keys, right?
Of course, as a popular, rapidly-growing service, GitHub was gaining users at a fair clip, to the point that the one big file that stored all the SSH keys was starting to visibly impact SSH login times.
This problem was also not going to get any better by itself.
Something Had To Be Done.
EY management was keen on making sure GitHub ran well, and so despite it not really being a hosting problem, they were willing to help fix this problem.
For some reason, the late, great, Ezra Zygmuntowitz pointed GitHub in my direction, and let me take the time to really get into the problem with the GitHub team.
After examining a variety of different possible solutions, we came to the conclusion that the least-worst option was to patch OpenSSH to lookup keys in a MySQL database, indexed on the key fingerprint.
We didn’t take this decision on a whim – it wasn’t a case of “yeah, sure, let’s just hack around with OpenSSH, what could possibly go wrong?”.
We knew it was potentially catastrophic if things went sideways, so you can imagine how much worse the other options available were.
Ensuring that this wouldn’t compromise security was a lot of the effort that went into the change.
In the end, though, we rolled it out in early April, and lo! SSH logins were fast, and we were pretty sure we wouldn’t have to worry about this problem for a long time to come.
Normally, you’d think “patching OpenSSH to make mass SSH logins super fast” would be a good story on its own.
But no, this is just the opening scene.
Chekov’s Gun Makes its Appearance
Fast forward a little under a month, to the first few days of May 2008.
I get a message from one of the GitHub team, saying that somehow users were able to access other users’ repos over SSH.
Naturally, as we’d recently rolled out the OpenSSH patch, which touched this very thing, the code I’d written was suspect number one, so I was called in to help.
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser Söze
Eventually, after more than a little debugging, we discovered that, somehow, there were two users with keys that had the same key fingerprint.
This absolutely shouldn’t happen – it’s a bit like winning the lottery twice in a row1 – unless the users had somehow shared their keys with each other, of course.
Still, it was worth investigating, just in case it was a web application bug, so the GitHub team reached out to the users impacted, to try and figure out what was going on.
The users professed no knowledge of each other, neither admitted to publicising their key, and couldn’t offer any explanation as to how the other person could possibly have gotten their key.
Then things went from “weird” to “what the…?”.
Because another pair of users showed up, sharing a key fingerprint – but it was a different shared key fingerprint.
The odds now have gone from “winning the lottery multiple times in a row” to as close to “this literally cannot happen” as makes no difference.
Once we were really, really confident that the OpenSSH patch wasn’t the cause of the problem, my involvement in the problem basically ended.
I wasn’t a GitHub employee, and EY had plenty of other customers who needed my help, so I wasn’t able to stay deeply involved in the on-going investigation of The Mystery of the Duplicate Keys.
However, the GitHub team did keep talking to the users involved, and managed to determine the only apparent common factor was that all the users claimed to be using Debian or Ubuntu systems, which was where their SSH keys would have been generated.
That was as far as the investigation had really gotten, when along came May 13, 2008.
Chekov’s Gun Goes Off
With the publication of DSA-1571-1, everything suddenly became clear.
Through a well-meaning but ultimately disasterous cleanup of OpenSSL’s randomness generation code, the Debian maintainer had inadvertently reduced the number of possible keys that could be generated by a given user from “bazillions” to a little over 32,000.
With so many people signing up to GitHub – some of them no doubt following best practice and freshly generating a separate key – it’s unsurprising that some collisions occurred.
You can imagine the sense of “oooooooh, so that’s what’s going on!” that rippled out once the issue was understood.
I was mostly glad that we had conclusive evidence that my OpenSSH patch wasn’t at fault, little knowing how much more contact I was to have with Debian weak keys in the future, running a huge store of known-compromised keys and using them to find misbehaving Certificate Authorities, amongst other things.
Lessons Learned
While I’ve not found a description of exactly when and how Luciano Bello discovered the vulnerability that became CVE-2008-0166, I presume he first came across it some time before it was disclosed – likely before GitHub tripped over it.
The stable Debian release that included the vulnerable code had been released a year earlier, so there was plenty of time for Luciano to have discovered key collisions and go “hmm, I wonder what’s going on here?”, then keep digging until the solution presented itself.
The thought “hmm, that’s odd”, followed by intense investigation, leading to the discovery of a major flaw is also what ultimately brought down the recent XZ backdoor.
The critical part of that sequence is the ability to do that intense investigation, though.
When I reflect on my brush with the Debian weak keys vulnerability, what sticks out to me is the fact that I didn’t do the deep investigation.
I wonder if Luciano hadn’t found it, how long it might have been before it was found.
The GitHub team would have continued investigating, presumably, and perhaps they (or I) would have eventually dug deep enough to find it.
But we were all super busy – myself, working support tickets at EY, and GitHub feverishly building features and fighting the fires in their rapidly-growing service.
As it was, Luciano was able to take the time to dig in and find out what was happening, but just like the XZ backdoor, I feel like we, as an industry, got a bit lucky that someone with the skills, time, and energy was on hand at the right time to make a huge difference.
It’s a luxury to be able to take the time to really dig into a problem, and it’s a luxury that most of us rarely have.
Perhaps an understated takeaway is that somehow we all need to wrestle back some time to follow our hunches and really dig into the things that make us go “hmm…”.
the odds are actually probably more like winning the lottery about twenty times in a row.
The numbers involved are staggeringly huge, so it’s easiest to just approximate it as “really, really unlikely”. ↩
Python includes some helping support for classes that are designed to just hold some data and not much more: Data Classes.
It uses plain Python type definitions to specify what you can have and some further information for every field.
This will then generate you some useful methods, like __init__ and __repr__, but on request also more.
But given that those type definitions are available to other code, a lot more can be done.
There exists several separate packages to work on data classes.
For example you can have data validation from JSON with dacite.
But Debian likes a pretty strange format usually called Deb822, which is in fact derived from the RFC 822 format of e-mail messages.
Those files includes single messages with a well known format.
So I'd like to introduce some Deb822 format support for Python Data Classes.
For now the code resides in the Debian Cloud tool.
Usage
Setup
It uses the standard data classes support and several helper functions.
Also you need to enable support for postponed evaluation of annotations.
This month I accepted 147 and rejected 12 packages. The overall number of packages that got accepted was 151.
If you file an RM bug, please do check whether there are reverse dependencies as well and file RM bugs for them. It is annoying and time-consuming when I have to do the moreinfo dance.
Debian LTS
This was my hundred-seventeenth month that I did some work for the Debian LTS initiative, started by Raphael Hertzog at Freexian.
During my allocated time I uploaded:
[DLA 3770-1] libnet-cidr-lite-perl security update for one CVE to fix IP parsing and ACLs based on the result
Unfortunately XZ happened at the end of month and I had to delay/intentionally delayed other uploads: they will appear as DLA-3781-1 and DLA-3784-1 in April
I also continued to work on qtbase-opensource-src and last but not least did a week of FD.
Debian ELTS
This month was the sixty-eighth ELTS month. During my allocated time I uploaded:
[ELA-1062-1]libnet-cidr-lite-perl security update for one CVE to improve parsing of IP addresses in Jessie and Stretch
Due to XZ I also delayed the uploads here. They will appear as ELA-1069-1 and DLA-1070-1 in April
I also continued on an update for qtbase-opensource-src in Stretch (and LTS and other releases as well) and did a week of FD.
Debian Printing
This month I uploaded new upstream or bugfix versions of:
The CNN story says Facebook apologized and said it was a mistake and was fixing it.
Color me skeptical, because today I saw this:
Yes, that’s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
Riiiiiight. Cybersecurity.
This isn’t even the first time they’ve done this to me.
That this same pattern has played out a second time — again with something that is a very slight challenege to Facebook — seems to validate my conclusion. Facebook lets all sort of hateful garbage infest their site, but anything about climate change — or their own censorship — gets removed, and this pattern persists for years.
There’s a reason I prefer Mastodon these days. You can find me there as @jgoerzen@floss.social.
So. I’ve written this blog post. And then I’m going to post it to Facebook. Let’s see if they try to censor me for a third time. Bring it, Facebook.
The moment you leave your laptop, say in a hotel room, you can no longer trust
your system as it could have been modified while you were away, which is also
known as the "evil maid" attack. Think you are safe because
you have a crypted disk? Well, if the boot partition is on the laptop itself,
it can be manipulated and you will not notice because the boot
partition can't be encrypted. The BIOS needs to access the MBR and boot loader
and that loads the Linux kernel, all unencrypted. There has been
some reports lately that the Linux cryptsetup is insecure because
you can spawn a root shell by hitting the enter key for 70 seconds. This is not
the threat to your system, really. If someone has physical access to your
hardware, he can get a root shell in less than a second by passing
init=/bin/bash as parameter to the Linux kernel in the boot loader regardless
if cryptsetup is used or not. The attacker can also use other ways like booting
a live system from CD/USB etc. The actual insecurity here is the unencrypted
boot partition and not some script that gets executed from it. So how to prevent
this physical access attack vector? Just keep reading this guide.
This guide explains how to install Debian securely on your laptop with using an
external USB boot disk, such as a standard USB memory stick. The disk inside the
laptop should not contain your /boot partition since that is an easy target for
manipulation. An attacker could for example change the boot scripts inside the
initrd image to capture your passphrase of your crypted volume. With an USB boot
partition, you can unplug the USB stick after the operating system has booted.
Best practice here is to have the USB stick together with your bunch of keys.
That way you will disconnect your USB stick early after the boot as finished so
you can put it back into your pocket.
Secure Hardware Assumptions
We have to assume here that the hardware you are using to download and verify
the install media is safe to use. Same applies with the hardware where you are
doing the fresh Debian install. Say the hardware does not contain any malware
in the form of code in EFI or other manipulation attempts that influence
the behavior of the operating system we are going to install.
Download Debian Install ISO
Feel free to use any Debian mirror and install flavor. For this guide I am using
the download mirror in Germany and the DVD install flavor.
To know if the ISO file was downloaded without modification we have to check the
hashsum of the file. The hashsum file can be found in the same directory as the
ISO file on the download mirror. With hashsums if a single bit differs in the
file, the resulting SHA512 sum will be completely different.
Calculate a local hashsum from the downloaded ISO file:
sha512sum debian-8.6.0-amd64-DVD-1.iso
Now you need to compare the hashsum with that is in the SHA512SUMS file. Since
the SHA512SUMS file contains the hashsums of all files that are in the same
directory you need to find the right one first. grep can do this for you:
grep debian-8.6.0-amd64-DVD-1.iso SHA512SUMS
Both commands executed after each other should show following output:
As you can see the hashsum found in the SHA512SUMS file matches with the locally
generated hashsum using the sha512sum command.
At this point we are not finished yet. These 2 matching hashsums just means
whatever was on the download server matches what we have received and stored
locally on your disk. The ISO file and SHA512SUM file could still be a
modified version!
And this is where GPG signatures chime in, covered in the next section.
Download GPG Signature File
GPG signature files usually have the .sign file name extension but could also
be named .asc. Download the signature file using wget:
Letting gpg verify the signature will fail at this point as we don't have the
public key of the signer:
$ gpg --verify SHA512SUMS.sign
gpg: assuming signed data in 'SHA512SUMS'
gpg: Signature made Mon 19 Sep 2016 12:23:47 AM HKT
gpg: using RSA key DA87E80D6294BE9B
gpg: Can't check signature: No public key
Downloading a key is trivial with gpg, but more importantly we need to verify
that this key (DA87E80D6294BE9B) is trustworthy, as it could also be a key of
the infamous man-in-the-middle.
Here you can find the GPG fingerprints of the official
signing keys used by Debian. The ending of the "Key fingerprint" line should
match the key id we found in the signature file from above.
Ok, we are almost there. Now we can run the command which checks if the signature
of the hashsum file we have, was not modified by anyone and matches what Debian
has generated and signed.
gpg: assuming signed data in 'SHA512SUMS'
gpg: Signature made Mon 19 Sep 2016 12:23:47 AM HKT
gpg: using RSA key DA87E80D6294BE9B
gpg: checking the trustdb
gpg: marginals needed: 3 completes needed: 1 trust model: pgp
gpg: depth: 0 valid: 1 signed: 0 trust: 0-, 0q, 0n, 0m, 0f, 1u
gpg: Good signature from "Debian CD signing key <debian-cd@lists.debian.org>" [unknown]
gpg: WARNING: This key is not certified with a trusted signature!
gpg: There is no indication that the signature belongs to the owner.
Primary key fingerprint: DF9B 9C49 EAA9 2984 3258 9D76 DA87 E80D 6294 BE9B
The important line in this output is the "Good signature from ..." one. It
still shows a warning since we never certified (signed) that Debian key. This
can be ignored at this point though.
Write ISO Image to Install Media
With a verified pristine ISO file we can finally start the install by writing it
to an USB stick or blank DVD. So use your favorite tool to write the ISO to your
install media and boot from it. I have used dd and a USB stick attached as
/dev/sdb.
There you need to select the "Guided, use entire disk and set up encrypted LVM"
option. After that select the built-in disk of your laptop, which usually is
sda but double check this before you go ahead, as it will overwrite the
data! The 137 GB disk in this case is the built-in disk and the 8 GB is the USB
stick.
It makes no difference at this point if you select "All files in one partition"
or "Separate /home partition". The USB boot partition can be selected a later
step.
Confirm that you want to overwrite your built-in disk shown as sda. It will take
a while as it will write random data to the disk to ensure there is no unencrypted
data left on the disk from previous installations for example.
Now you need to enter your passphrase that will be used to protect the private
key of the crypt volume. Choose something long enough like a sentence and don't
forget the passphrase else you can no longer access your data! Don't save the
passphrase on any computer, smartphone or password manager. If you want to make
a backup of your passphrase then use a ball pen and paper and store the paper
backup in a secure location.
The installer will show you a summary of the partitioning as shown above but
we need to make the change for the USB boot disk. At the moment it wants to put
/boot on sda which is the built-in disk, while our USB stick is sdb. Select
/boot and hit enter, after that select "Delete this partition".
After /boot was deleted we can create /boot on the USB stick shown as sdb.
Select sdb and hit enter. It will ask if you want to create an empty partition
table. Confirm that question with yes.
The partition summary shows sdb with no partitions on it. Select FREE SPACE
and select "Create a new partition". Confirm the suggested partition size.
Confirm the partition type to be "Primary".
It is time to tell the installer to use this new partition on the USB stick
(sdb1) as /boot partition. Select "Mount point: /home" and in the next dialog
select "/boot - static files of the boot loader" as shown below:
Confirm the made changes by selecting "Done setting up the partition".
The final partitioning should look now like the following screenshot:
If the partition summary looks good, go ahead with the installation by selecting
"Finish partitioning and write changes to disk".
When the installer asks if it should force EFI, then select no, as EFI is not
going to protect you.
Finish the installation as usual, select your preferred desktop environment etc.
GRUB Boot Loader
Confirm the dialog that wants to install GRUB to the master boot record. Here it
is important to install it to the USB stick and not your built-in SATA/SSD disk!
So select sdb (the USB stick) in the next dialog.
First Boot from USB
Once everything is installed, you can boot from your USB stick. As simple test
you can unplug your USB stick and the boot should fail with "no operating
system found" or similar error message from the BIOS. If it doesn't boot even
though the USB stick is connected, then most likely your BIOS is not configured
to boot from USB media. Also a blank screen and nothing happening is usually
meaning the BIOS can't find a boot device. You need to change the boot setting
in your BIOS. As the steps are very different for each BIOS, I can't provide a
detailed step-by-step list here.
Usually you can enter the BIOS using F1, F2 or F12 after powering on your
computer. In the BIOS there is a menu to configure the boot order. In that list
it should show USB disk/storage as the first position. After you have made the
changes save and exit the BIOS. Now it will boot from your USB stick first and
GRUB will show up and proceeds with the boot process till it will ask for your
passphrase to unlock the crypt volume.
Unmount /boot partition after Boot
If you boot your laptop from the USB stick, we want to remove the stick after it
has finished booting. This will prevent an attacker to make modifications to
your USB stick. To avoid data loss, we should not simply unplug the USB stick
but unmount /boot first and then unplug the stick. Good news is that we can
automate this unmounting and you just need to unplug the stick after the laptop
has finished booting to your login screen.
Just add this line to your /etc/rc.local file:
umount /boot
After boot you can once verify that it automatically unmounts /boot for you by
running:
mount | grep /boot
If that command produces no output, then /boot is not mounted and you can
safely unplug the USB stick.
Final Words
From time to time you need to upgrade your Linux kernel of course which is on
the /boot partition. This can still be done the regular way using apt-get
upgrade, except that you need to mount /boot before that and unmount it again
after the kernel upgrade.
Enjoy your secured laptop. Now you can leave it in a hotel room without the
possibility of someone trying you obtain your passphrase by putting a key logger
in your boot partition. All the attacker will see is a fully encrypted harddisk.
If he tries to mess with your crypted disk, you will notice as the decryption
will fail.
Disclaimer: there are still other attack vectors possible, but they are much
harder to do. Your hardware or BIOS can still be modified. But not by holding
down the enter key for 70 seconds or by booting a live system.
Trying to explain analogue clock. It's hard to
explain. Tried adding some things for affordance, and it is
still not enough. So it's not obvious which arm is the hour
and which arm is the minute.
analog clock
Armadillo is a powerful
and expressive C++ template library for linear algebra and scientific
computing. It aims towards a good balance between speed and ease of use,
has a syntax deliberately close to Matlab, and is useful for algorithm
development directly in C++, or quick conversion of research code into
production environments. RcppArmadillo
integrates this library with the R environment and language–and is
widely used by (currently) 1136 other packages on CRAN, downloaded 33.5 million
times (per the partial logs from the cloud mirrors of CRAN), and the CSDA paper (preprint
/ vignette) by Conrad and myself has been cited 578 times according
to Google Scholar.
This release brings a new upstream bugfix release Armadillo 12.8.2
prepared by Conrad two days
ago. It took the usual day to noodle over 1100+ reverse dependencies and
ensure two failures were independent of the upgrade (i.e., “no
change to worse” in CRAN
parlance). It took CRAN another
because we hit a random network outage for (spurious) NOTE on a remote
URL, and were then caught in the shrapnel from another large package
ecosystem update spuriously pointing some build failures that were due
to a missing rebuild to us. All good, as human intervention comes to the
rescue.
The set of changes since the last CRAN release follows.
Changes
in RcppArmadillo version 0.12.8.2.0 (2024-04-02)
Upgraded to Armadillo release 12.8.2 (Cortisol Injector)
Workaround for FFTW3 header clash
Workaround in testing framework for issue under macOS
The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The DPL is the official representative of representative of The Debian Project tasked with managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last Bits from the DPL
post to Debian recently and his hopes for the future of Debian.
Recently, we sat with the two present candidates for the DPL position asking
questions to find out who they really are in a series of interviews about
their platforms, visions for Debian, lives, and even their favorite text
editors. The interviews were conducted by disaster2life (Yashraj Moghe) and
made available from video and audio transcriptions:
Editors' note:
This is our official return to Debian interviews, readers should stay tuned
for more upcoming interviews with Developers and other important figures in
Debian as part of our "Meet your Debian Developer" series. We used the
following tools and services: Turboscribe.ai for the
transcription from the audio and video files, IRC: Oftc.net for
communication, Jitsi meet for interviews, and
Open Broadcaster Software (OBS) for editing and
video. While we encountered many technical difficulties in the return to this
process, we are still able and proud to present the transcripts of the
interviews edited only in a few areas for readability.
Hi Sruthi, so for the first question, who are you and could you tell us a little
bit about yourself?
[Sruthi]:
I usually talk about me whenever I am talking about answering the question who
am I, I usually say like I am a librarian turned free software enthusiast and
a Debian Developer. So I had no technical background and I learned, I was
introduced to free software through my husband and then I learned Debian
packaging, and eventually I became a Debian Developer. So I always give my
example to people who say I am not technically inclined, I don't have technical
background so I can't contribute to free software.
So yeah, that's what I refer to myself.
For the next question, could you tell me what do you do in Debian, and could
you mention your story up until here today?
[Sruthi]:
Okay, so let me start from my initial days in Debian. I started contributing to
Debian, my first contribution was a Tibetan font. We went to a Tibetan place
and they were saying they didn't have a font in Linux.
So that's how I started contributing. Then I moved on to Ruby packages, then I
have some JavaScript and Go packages, all dependencies of GitLab. So I was
involved with maintaining GitLab for some time, now I'm not very active there.
But yeah, so GitLab was the main package I was contributing to since I
contributed since 2016 to maybe like 2020 or something. Later I have come
[over to] packaging. Now I am part of some of the teams, delegated teams, like
community team and outreach team, as well as the Debconf committee. And the
biggest, I think, my activity in Debian, I would say is organizing Debconf
2023. So it was a great experience and yeah, so that's my story in Debian.
So what are three key terms about you and your candidacy?
[Sruthi]:
Okay, let me first think about it. For candidacy, I can start with diversity is
one point I started expressing from the first time I contested for DPL. But to
be honest, that's the main point I want to bring.
[Yashraj]:
So for diversity, if you could break down your thoughts on diversity and make
them, [about] your three points including diversity.
[Sruthi]:
So in addition to, eventually when starting it was just diversity. Now I have
like a bit more ideas, like community, like I want to be a leader for the
Debian community. More than, I don't know, maybe people may not agree, but I
would say I want to be a leader of Debian community rather than a Debian operating system.
I connect to community more and third point I would say.
The term of a DPL lasts for an year. So what do you think during, what would you
try to do during that, that you can't do from your position now?
[Sruthi]:
Okay. So I, like, I am very happy with the structure of Debian and how things
work in Debian. Like you can do almost a lot of things, like almost all things
without being a DPL.
Whatever change you want to bring about or whatever you want to do, you can do
without being a DPL. Anyone, like every DD has the same rights. Only things I
feel [the] DPL has hold on are mainly the budget or the funding part, which like,
that's where they do the decision making part.
And then comes like, and one advantage of DPL driving some idea is that somehow
people tend to listen to that with more, like, tend to give more attention to
what DPL is saying rather than a normal DD. So I wanted to, like, I have
answered some of the questions on how to, how I plan to do the financial
budgeting part, how I want to handle, like, and the other thing is using the
extra attention that I get as a DPL, I would like to obviously start with the
diversity aspect in Debian. And yeah, like, I, what I want to do is not, like,
be a leader and say, like, take Debian to one direction where I want to go, but
I would rather take suggestions and inputs from the whole community and go about
with that.
So yes, that's what I would say.
And taking a less serious question now, what is your preferred text editor?
[Sruthi]:
Vim.
[Yashraj]:
Vim, wholeheartedly team Vim?
[Sruthi]:
Yes.
[Yashraj]:
Great. Well, this was made in Vim, all the text for this.
[Sruthi]:
So, like, since you mentioned extra data, I'll give my example, like, it's just
a fun note, when I started contributing to Debian, as I mentioned, I didn't have
any knowledge about free software, like Debian, and I was not used to even
using Linux. So, and I didn't have experience with these text editors. So, when
I started contributing, I used to do the editing part using gedit.
So, that's how I started. Eventually, I moved to Nano, and once I reached Vim,
I didn't move on.
Team Vim. Next question. What, what do you think is the importance of
the Debian project in the world today? And where would you like to see it in
10 years, like 10 years into the future?
[Sruthi]:
Okay. So, Debian, as we all know, is referred to as the universal operating
system without, like, it is said for a reason. We have hundreds and hundreds of
operating systems, like Linux, distributions based on Debian.
So, I believe Debian, like even now, Debian has good influence on the, at least
on the Linux or Linux ecosystem. So, what we implement in Debian has, like, is
going to affect quite a lot of, like, a very good percentage of people using
Linux. So, yes.
So, I think Debian is one of the leading Linux distributions. And I think in
10 years, we should be able to reach a position, like, where we are not, like,
even now, like, even these many years after having Linux, we face a lot of
problems in newer and newer hardware coming up and installing on them is a big
problem. Like, firmwares and all those things are getting more and more
complicated.
Like, it should be getting simpler, but it's getting more and more complicated.
So, I, one thing I would imagine, like, I don't know if we will ever reach
there, but I would imagine that eventually with the Debian, we should be able
to have some, at least a few of the hardware developers or hardware producers
have Debian pre-installed and those kind of things. Like, not, like, become,
I'm not saying it's all, it's also available right now.
What I'm saying is that it becomes prominent enough to be opted as, like, default
distro.
What part of Debian has made you And what part of the project has kept you going
all through these years?
[Sruthi]:
Okay. So, I started to contribute in 2016, and I was part of the team doing
GitLab packaging, and we did have a lot of training workshops and those kind of
things within India. And I was, like, I had interacted with some of the Indian
DDs, but I never got, like, even through chat or mail.
I didn't have a lot of interaction with the rest of the world, DDs. And the 2019
Debconf changed my whole perspective about Debian. Before that, I wasn't, like,
even, I was interested in free software.
I was doing the technical stuff and all. But after DebConf, my whole idea has
been, like, my focus changed to the community. Debian community is a very
welcoming, very interesting community to be with.
And so, I believe that, like, 2019 DebConf was a for me. And that kept, from
2019, my focus has been to how to support, like, how, I moved to the community
part of Debian from there. Then in 2020 I became part of the community team,
and, like, I started being part of other teams.
So, these, I would say, the Debian community is the one, like, aspect of Debian
that keeps me whole, keeps me held on to the Debian ecosystem as a whole.
Continuing to speak about Debian, what do you think, what is the first thing that
comes to your mind when you think of Debian, like, the word, the community,
what's the first thing?
[Sruthi]:
I think I may sound like a broken record or something.
[Yashraj]:
No, no.
[Sruthi]:
Again, I would say the Debian community, like, it's the people who makes
Debian, that makes Debian special.
Like, apart from that, if I say, I would say I'm very, like, one part of Debian
that makes me very happy is the, how the governing system of Debian works, the
Debian constitution and all those things, like, it's a very unique thing for
Debian. And, and it's like, when people say you can't work without a proper,
like, establishment or even somebody deciding everything for you, it's
difficult. When people say, like, we have been, Debian has been proving
it for quite a long time now, that it's possible.
So, so that's one thing I believe, like, that's one unique point. And I am very
proud about that.
What areas do you think Debian is failing in, how can it (that standing) be improved?
[Sruthi]:
So, I think where Debian is failing now is getting new people into Debian.
Like, I don't remember, like, exactly the answer. But I remember hearing
someone mention, like, the average age of a Debian Developer is, like, above 40
or 45 or something, like, exact age, I don't remember.
But it's like, Debian is getting old. Like, the people in Debian are getting old
and we are not getting enough of new people into Debian. And that's very
important to have people, like, new people coming up.
Otherwise, eventually, like, after a few years, nobody, like, we won't have
enough people to take the project forward. So, yeah, I believe that is where we
need to work on. We are doing some efforts, like, being part of GSOC or
outreachy and having maybe other events, like, local events. Like, we used to
have a lot of Debian packaging workshops in India. And those kind of, I think,
in Brazil and all, they all have, like, local communities are doing. But we are
not very successful in retaining the people who maybe come and try out things.
But we are not very good at retaining the people, like, retaining people who
come. So, we need to work on those things. Right now, I don't have a solid
answer for that.
But one thing, like, I was thinking about is, like, having a Debian specific
outreach project, wherein the focus will be about the Debian, like, starting
will be more on, like, usually what happens in GSOC and outreach is that people
come, have the, do the contributions, and they go back. Like, they don't have
that connection with the Debian, like, Debian community or Debian project. So,
what I envision with these, the Debian outreach, the Debian specific outreach
is that we have some part of the internship, like, even before starting the
internship, we have some sessions and, like, with the people in Debian having,
like, getting them introduced to the Debian philosophy and Debian community and
Debian, how Debian works.
And those things, we focus on that. And then we move on to the technical
internship parts. So, I believe this could do some good in having, like, when
you have people you can connect to, you tend to stay back in a project mode.
When you feel something more than, like, right now, we have so many technical
stuff to do, like, the choice for a college student is endless. So, if they
want, if they stay back for something, like, maybe for Debian, I would say, we
need to have them connected to the Debian project before we go into technical
parts. Like, technical parts, like, there are other things as well, where they
can go and do the technical part, but, like, they can come here, like, yeah.
So, that's what I was saying. Focused outreach projects is one thing. That's
just one.
That's not enough. We need more of, like, more ideas to have more new people
come up. And I'm very happy with, like, the DebConf thing. We tend to get more
and more people from the places where we have a DebConf. Brazil is an example.
After the Debconf, they have quite a good improvement on Debian contributors.
And I think in India also, it did give a good result. Like, we have more people
contributing and staying back and those things. So, yeah.
So, these were the things I would say, like, we can do to improve.
For the final question, what field in free software do you, what
field in free software generally do you think requires the most work to be
put into it? What do you think is Debian's part in that field?
[Sruthi]:
Okay. Like, right now, what comes to my mind is the free software licenses
parts. Like, we have a lot of free software licenses, and there are non-free
software licenses.
But currently, I feel free software is having a big problem in enforcing these
licenses. Like, there are, there may be big corporations or like some people who
take up the whole, the code and may not follow the whole, for example, the GPL
licenses. Like, we don't know how much of those, how much of the free softwares
are used in the bigger things.
Yeah, I agree. There are a lot of corporations who are afraid to touch free
software. But there would be good amount of free software, free work that
converts into property, things violating the free software licenses and those
things.
And we do not have the kind of like, we have SFLC, SFC, etc. But still, we do
not have the ability to go behind and trace and implement the licenses. So,
enforce those licenses and bring people who are violating the licenses forward
and those kind of things is challenging because one thing is it takes time,
like, and most importantly, money is required for the legal stuff.
And not always people who like people who make small software, or maybe big,
but they may not have the kind of time and money to have these things enforced.
So, that's a big challenge free software is facing, especially in our current
scenario. I feel we are having those, like, we need to find ways how we can get
it sorted.
I don't have an answer right now what to do. But this is a challenge I felt
like and Debian's part in that. Yeah, as I said, I don't have a solution for
that.
But the Debian, so DFSG and Debian sticking on to the free software licenses is
a good support, I think.
So, that was the final question, Do you have anything else you want to mention
for anyone watching this?
[Sruthi]:
Not really, like, I am happy, like, I think I was able to answer the questions.
And yeah, I would say who is watching. I won't say like, I'm the best DPL
candidate, you can't have a better one or something.
I stand for a reason. And if you believe in that, or the Debian community and
Debian diversity, and those kinds of things, if you believe it, I hope you
would be interested, like, you would want to vote for me. That's it.
Like, I'm not, I'll make it very clear. I'm not doing a technical leadership
part here. So, those, I can't convince people who want technical leadership to
vote for me.
But I would say people who connect with me, I hope they vote for me.
The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The Project Leader is the official representative of The Debian Project tasked with
managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last Bits from the DPL
post to Debian recently and his hopes for the future of Debian.
Recently, we sat with the two present candidates for the DPL position asking
questions to find out who they really are in a series of interviews about
their platforms, visions for Debian, lives, and even their favorite text
editors. The interviews were conducted by disaster2life (Yashraj Moghe) and
made available from video and audio transcriptions:
Editors' note:
This is our official return to Debian interviews, readers should stay tuned
for more upcoming interviews with Developers and other important figures in
Debian as part of our "Meet your Debian Developer" series. We used the
following tools and services: Turboscribe.ai for the
transcription from the audio and video files, IRC: Oftc.net for
communication, Jitsi meet for interviews, and
Open Broadcaster Software (OBS) for editing and
video. While we encountered many technical difficulties in the return to this
process, we are still able and proud to present the transcripts of the
interviews edited only in a few areas for readability.
2024 Debian Project Leader Candidate: Andrea Tille
Andreas' Interview
Who are you? Tell us a little about yourself.
[Andreas]:
How am I? Well, I'm, as I wrote in my platform, I'm a proud grandfather doing a
lot of free software stuff, doing a lot of sports, have some goals in mind which
I like to do and hopefully for the best of Debian.
And How are you today?
[Andreas]:
How I'm doing today? Well, actually I have some headaches but it's fine for the
interview.
So, usually I feel very good. Spring was coming here and today it's raining and
I plan to do a bicycle tour tomorrow and hope that I do not get really sick but
yeah, for the interview it's fine.
What do you do in Debian? Could you mention your story here?
[Andreas]:
Yeah, well, I started with Debian kind of an accident because I wanted to have
some package salvaged which is called WordNet. It's a monolingual dictionary and
I did not really plan to do more than maybe 10 packages or so. I had some kind
of training with xTeddy which is totally unimportant, a cute teddy you can put
on your desktop.
So, and then well, more or less I thought how can I make Debian attractive for
my employer which is a medical institute and so on. It could make sense to
package bioinformatics and medicine software and it somehow evolved in a
direction I did neither expect it nor wanted to do, that I'm currently the most
busy uploader in Debian, created several teams around it.
DebianMate is very well known from me. I created the Blends team to create teams
and techniques around what we are doing which was Debian TIS, Debian Edu, Debian
Science and so on and I also created the packaging team for R, for the
statistics package R which is technically based and not topic based. All these
blends are covering a certain topic and R is just needed by lots of these
blends.
So, yeah, and to cope with all this I have written a script which is routing an
update to manage all these uploads more or less automatically. So, I think I had
one day where I uploaded 21 new packages but it's just automatically generated,
right? So, it's on one day more than I ever planned to do.
What is the first thing you think of when you think of Debian?
Editors' note: The question was misunderstood as the “worst thing you think of when you
think of Debian”
[Andreas]:
The worst thing I think about Debian, it's complicated. I think today on Debian
board I was asked about the technical progress I want to make and in my opinion
we need to standardize things inside Debian. For instance, bringing all the
packages to salsa, follow some common standards, some common workflow which is
extremely helpful.
As I said, if I'm that productive with my own packages we can adopt this in
general, at least in most cases I think. I made a lot of good experience by the
support of well-formed teams. Well-formed teams are those teams where people
support each other, help each other.
For instance, how to say, I'm a physicist by profession so I'm not an IT expert.
I can tell apart what works and what not but I'm not an expert in those
packages. I do and the amount of packages is so high that I do not even
understand all the techniques they are covering like Go, Rust and something like
this.
And I also don't speak Java and I had a problem once in the middle of the night
and I've sent the email to the list and was a Java problem and I woke up in the
morning and it was solved. This is what I call a team. I don't call a team some
common repository that is used by random people for different packages also but
it's working together, don't hesitate to solve other people's problems and
permit people to get active.
This is what I call a team and this is also something I observed in, it's hard
to give a percentage, in a lot of other teams but we have other people who do
not even understand the concept of the team. Why is working together make some
advantage and this is also a tough thing. I [would] like to tackle in my term if
I get elected to form solid teams using the common workflow. This is one thing.
The other thing is that we have a lot of good people in our infrastructure like
FTP masters, DSA and so on. I have the feeling they have a lot of work and are
working more or less on their limits, and I like to talk to them [to ask] what
kind of change we could do to move that limits or move their personal health to
the better side.
The DPL term lasts for a year, What would you do during that you couldn't do now?
[Andreas]:
Yeah, well this is basically what I said are my main issues. I need to admit I
have no really clear imagination what kind of tasks will come to me as a DPL
because all these financial issues and law issues possible and issues [that]
people who are not really friendly to Debian might create. I'm afraid these
things might occupy a lot of time and I can't say much about this because I
simply don't know.
What are three key terms about you and your candidacy?
[Andreas]:
As I said, I like to work on standards, I’d like to make Debian try [to get
it right so] that people don't get overworked, this third key point is be
inviting to newcomers, to everybody who wants to come. Yeah, I also mentioned in
my term this diversity issue, geographical and from gender point of view. This
may be the three points I consider most important.
Preferred text editor?
[Andreas]:
Yeah, my preferred one? Ah, well, I have no preferred text editor. I'm using the
Midnight Commander very frequently which has an internal editor which is
convenient for small text. For other things, I usually use VI but I also use
Emacs from time to time. So, no, I have not preferred text editor. Whatever
works nicely for me.
What is the importance of the community in the Debian Project? How would
like to see it evolving over the next few years?
[Andreas]:
Yeah, I think the community is extremely important. So, I was on a lot of
DebConfs. I think it's not really 20 but 17 or 18 DebCons and I really enjoyed
these events every year because I met so many friends and met so many
interesting people that it's really enriching my life and those who I never met
in person but have read interesting things and yeah, Debian community makes
really a part of my life.
And how do you think it should evolve specifically?
[Andreas]:
Yeah, for instance, last year in Kochi, it became even clearer to me that the
geographical diversity is a really strong point. Just discussing with some women
from India who is afraid about not coming next year to Busan because there's a
problem with Shanghai and so on. I'm not really sure how we can solve this but I
think this is a problem at least I wish to tackle and yeah, this is an
interesting point, the geographical diversity and I'm running the so-called
mentoring of the month.
This is a small project to attract newcomers for the Debian Med team which has
the focus on medical packages and I learned that we had always men applying for
this and so I said, okay, I dropped the constraint of medical packages.
Any topic is fine, I teach you packaging but it must be someone who does not
consider himself a man. I got only two applicants, no, actually, I got one
applicant and one response which was kind of strange if I'm hunting for women or
so.
I did not understand but I got one response and interestingly, it was for me one
of the least expected counters. It was from Iran and I met a very nice woman,
very open, very skilled and gifted and did a good job or have even lose contact
today and maybe we need more actively approach groups that are underrepresented.
I don't know if what's a good means which I did but at least I tried and so I
try to think about these kind of things.
What part of Debian has made you smile? What part of the project has kept
you going all through the years?
[Andreas]:
Well, the card game which is called Mao on the DebConf made me smile all the
time. I admit I joined only two or three times even if I really love this kind
of games but I was occupied by other stuff so this made me really smile. I also
think the first online DebConf in 2020 made me smile because we had this kind of
short video sequences and I tried to make a funny video sequence about every
DebConf I attended before. This is really funny moments but yeah, it's not only
smile but yeah.
One thing maybe it's totally unconnected to Debian but I learned personally
something in Debian that we have a do-ocracy and you can do things which you
think that are right if not going in between someone else, right? So respect
everybody else but otherwise you can do so.
And in 2020 I also started to take trees which are growing widely in my garden
and plant them into the woods because in our woods a lot of trees are dying and
so I just do something because I can. I have the resource to do something, take
the small tree and bring it into the woods because it does not harm anybody. I
asked the forester if it is okay, yes, yes, okay. So everybody can do so but I
think the idea to do something like this came also because of the free software
idea. You have the resources, you have the computer, you can do something and
you do something productive, right? And when thinking about this I think it was
also my Debian work.
Meanwhile I have planted more than 3,000 trees so it's not a small number but
yeah, I enjoy this.
What part of Debian would you have some criticisms for?
[Andreas]:
Yeah, it's basically the same as I said before. We need more standards to work
together. I do not want to repeat this but this is what I think, yeah.
What field in Free Software generally do you think requires the most work
to be put into it? What do you think is Debian's part in the field?
[Andreas]:
It's also in general, the thing is the fact that I'm maintaining packages which
are usually as modern software is maintained in Git, which is fine but we have
some software which is at Sourceport, we have software laying around somewhere,
we have software where Debian somehow became Upstream because nobody is caring
anymore and free software is very different in several things, ways and well, I
in principle like freedom of choice which is the basic of all our work.
Sometimes this freedom goes in the way of productivity because everybody is free
to re-implement. You asked me for the most favorite editor. In principle one
really good working editor would be great to have and would work and we have
maybe 500 in Debian or so, I don't know.
I could imagine if people would concentrate and say five instead of 500 editors,
we could get more productive, right? But I know this will not happen, right? But
I think this is one thing which goes in the way of making things smooth and
productive and we could have more manpower to replace one person who's [having]
children, doing some other stuff and can't continue working on something and
maybe this is a problem I will not solve, definitely not, but which I see.
What do you think is Debian's part in the field?
[Andreas]:
Yeah, well, okay, we can bring together different Upstreams, so we are building
some packages and have some general overview about similar things and can say,
oh, you are doing this and some other person is doing more or less the same, do
you want to join each other or so, but this is kind of a channel we have to our
Upstreams which is probably not very successful.
It starts with code copies of some libraries which are changed a little bit,
which is fine license-wise, but not so helpful for different things and so I've
tried to convince those Upstreams to forward their patches to the original one,
but for this and I think we could do some kind of, yeah, [find] someone who
brings Upstream together or to make them stop their forking stuff, but it costs
a lot of energy and we probably don't have this and it's also not realistic that
we can really help with this problem.
Do you have any questions for me?
[Andreas]:
I enjoyed the interview, I enjoyed seeing you again after half a year or so.
Yeah, actually I've seen you in the eating room or cheese and wine party or so,
I do not remember we had to really talk together, but yeah, people around, yeah,
for sure. Yeah.
You’ve probably heard of the recent backdoor in xz. There have been a lot of takes on this, most of them boiling down to some version of:
The problem here is with Open Source Software.
I want to say not only is that view so myopic that it pushes towards the incorrect, but also it blinds us to more serious problems.
Now, I don’t pretend that there are no problems in the FLOSS community. There have been various pieces written about what this issue says about the FLOSS community (usually without actionable solutions). I’m not here to say those pieces are wrong. Just that there’s a bigger picture.
So with this xz issue, it may well be a state actor (aka “spy”) that added this malicious code to xz. We also know that proprietary software and systems can be vulnerable. For instance, a Twitter whistleblower revealed that Twitter employed Indian and Chinese spies, some knowingly. A recent report pointed to security lapses at Microsoft, including “preventable” lapses in security. According to the Wikipedia article on the SolarWinds attack, it was facilitated by various kinds of carelessness, including passwords being posted to Github and weak default passwords. They directly distributed malware-infested updates, encouraged customers to disable anti-malware tools when installing SolarWinds products, and so forth.
It would be naive indeed to assume that there aren’t black hat actors among the legions of programmers employed by companies that outsource work to low-cost countries — some of which have challenges with bribery.
So, given all this, we can’t really say the problem is Open Source. Maybe it’s more broad:
The problem here is with software.
Maybe that inches us closer, but is it really accurate? We have all heard of Boeing’s recent issues, which seem to have some element of root causes in corporate carelessness, cost-cutting, and outsourcing. That sounds rather similar to the SolarWinds issue, doesn’t it?
Well then, the problem is capitalism.
Maybe it has a role to play, but isn’t it a little too easy to just say “capitalism” and throw up our hands helplessly, just as some do with FLOSS as at the start of this article? After all, capitalism also brought us plenty of products of very high quality over the years. When we can point to successful, non-careless products — and I own some of them (for instance, my Framework laptop). We clearly haven’t reached the root cause yet.
And besides, what would you replace it with? All the major alternatives that have been tried have even stronger downsides. Maybe you replace it with “better regulated capitalism”, but that’s still capitalism.
Then the problem must be with consumers.
As this argument would go, it’s consumers’ buying patterns that drive problems. Buyers — individual and corporate — seek flashy features and low cost, prizing those over quality and security.
But consumers are also people, and some fraction of them are quite capable of writing fantastic software, and in fact, do so.
So what we need is some way to seize control. Some way to do what is right, despite the pressures of consumers or corporations.
Ah yes, dear reader, you have been slogging through all these paragraphs and now realize I have been leading you to this:
Then the solution is Open Source.
Indeed. Faults and all, FLOSS is the most successful movement I know where people are bringing us back to the commons: working and volunteering for the common good, unleashing a thousand creative variants on a theme, iterating in every direction imaginable. We have FLOSS being vital parts of everything from $30 Raspberry Pis to space missions. It is bringing education and communication to impoverished parts of the world. It lets everyone write and release software. And, unlike the SolarWinds and Twitter issues, it exposes both clever solutions and security flaws to the world.
If an authentication process in Windows got slower, we would all shrug and mutter “Microsoft” under our breath. Because, really, what else can we do? We have no agency with Windows.
If an authentication process in Linux gets slower, anybody that’s interested — anybody at all — can dive in and ask “why” and trace it down to root causes.
Some look at this and say “FLOSS is responsible for this mess.” I look at it and say, “this would be so much worse if it wasn’t FLOSS” — and experience backs me up on this.
FLOSS doesn’t prevent security issues itself.
What it does do is give capabilities to us all. The ability to investigate. Ability to fix. Yes, even the ability to break — and its cousin, the power to learn.
We are pleased to announce that Proxmox
has committed to sponsor DebConf24 as a
Platinum Sponsor.
Proxmox provides powerful and user-friendly open-source server software.
Enterprises of all sizes and industries use Proxmox solutions to deploy
efficient and simplified IT infrastructures, minimize total cost of ownership,
and avoid vendor lock-in. Proxmox also offers commercial support, training
services, and an extensive partner ecosystem to ensure business continuity
for its customers. Proxmox Server Solutions GmbH was established in 2005 and is
headquartered in Vienna, Austria.
Proxmox builds its product offerings on top of the Debian operating system.
With this commitment as Platinum Sponsor, Proxmox is contributing to make
possible our annual conference, and directly supporting the progress of Debian
and Free Software, helping to strengthen the community that continues to
collaborate on Debian projects throughout the rest of the year.
Thank you very much, Proxmox, for your support of DebConf24!
Become a sponsor too!
DebConf24 will take place from 28th July to 4th August 2024 in Busan,
South Korea, and will be preceded by DebCamp, from 21st to 27th July 2024.
DebConf24 is accepting sponsors! Interested companies and organizations may
contact the DebConf team through sponsors@debconf.org, or
visit the Become a DebConf Sponsor website.
A short status update of what happened on my side last month. I spent
quiet a bit of time reviewing new, code (thanks!) as well as
maintenance to keep things going but we also have some improvements:
Add support for progress indicator and counts to lockscreen launcher entries: Merge request,
Demo using Phosh-EV's charge status as example (Merge request)
Was the ssh backdoor the only goal that "Jia Tan" was pursuing
with their multi-year operation against xz?
I doubt it, and if not, then every fix so far has been incomplete,
because everything is still running code written by that entity.
If we assume that they had a multilayered plan, that their every action was
calculated and malicious, then we have to think about the full threat
surface of using xz. This quickly gets into nightmare scenarios of the
"trusting trust" variety.
What if xz contains a hidden buffer overflow or other vulnerability, that
can be exploited by the xz file it's decompressing? This would let the
attacker target other packages, as needed.
Let's say they want to target gcc. Well, gcc contains a lot of
documentation, which includes png images. So they spend a while getting
accepted as a documentation contributor on that project, and get added to
it a png file that is specially constructed, it has additional binary data
appended that exploits the buffer overflow. And instructs xz to modify the
source code that comes later when decompressing gcc.tar.xz.
More likely, they wouldn't bother with an actual trusting trust attack on
gcc, which would be a lot of work to get right. One problem with the ssh
backdoor is that well, not all servers on the internet run ssh. (Or
systemd.) So webservers seem a likely target of this kind of second stage
attack. Apache's docs include png files, nginx does not, but there's always
scope to add improved documentation to a project.
When would such a vulnerability have been introduced? In February, "Jia
Tan" wrote a new decoder for xz.
This added 1000+ lines of new C code across several commits. So much code
and in just the right place to insert something like this. And why take on
such a significant project just two months before inserting the ssh
backdoor? "Jia Tan" was already fully accepted as maintainer, and doing
lots of other work, it doesn't seem to me that they needed to start this
rewrite as part of their cover.
They were working closely with xz's author Lasse Collin in this, by
indications exchanging patches offlist as they developed it. So Lasse
Collin's commits in this time period are also worth scrutiny, because
they could have been influenced by "Jia Tan". One that
caught my eye comes immediately afterwards:
"prepares the code for alternative C versions and inline assembly"
Multiple versions and assembly mean even more places to hide such a
security hole.
I stress that I have not found such a security hole, I'm only considering
what the worst case possibilities are. I think we need to fully consider
them in order to decide how to fully wrap up this mess.
Whether such stealthy security holes have been introduced into xz by "Jia
Tan" or not, there are definitely indications that the ssh backdoor was not
the end of what they had planned.
For one thing, the "test file" based system they introduced
was extensible.
They could have been planning to add more test files later, that backdoored
xz in further ways.
And then there's the matter of the disabling of the Landlock sandbox. This
was not necessary for the ssh backdoor, because the sandbox is only used by
the xz command, not by liblzma. So why did they potentially tip their
hand by adding that rogue "." that disables the sandbox?
A sandbox would not prevent the kind of attack I discuss above, where xz is
just modifying code that it decompresses. Disabling the sandbox suggests
that they were going to make xz run arbitrary code, that perhaps wrote to
files it shouldn't be touching, to install a backdoor in the system.
Both deb and rpm use xz compression, and with the sandbox disabled,
whether they link with liblzma or run the xz command, a backdoored xz can
write to any file on the system while dpkg or rpm is running and noone is
likely to notice, because that's the kind of thing a package manager does.
My impression is that all of this was well planned and they were in it for
the long haul. They had no reason to stop with backdooring ssh, except for
the risk of additional exposure. But they decided to take that risk, with
the sandbox disabling. So they planned to do more, and every commit
by "Jia Tan", and really every commit that they could have influenced
needs to be distrusted.
I do have a xz-unscathed
fork which I've carefully constructed to avoid all "Jia Tan" involved
commits. It feels good to not need to worry about dpkg and tar.
I only plan to maintain this fork minimally, eg security fixes.
Hopefully Lasse Collin will consider these possibilities and address
them in his response to the attack.
First, thanks to Samuel Henrique for giving notice of recent Firefox
CVEs in Debian
testing/unstable.
At the time I didn't want to upgrade my system (Debian Sid) due to the ongoing
t64 transition transition,
so I decided I could install the Firefox Flatpak app instead, and why not stick
to it long-term?
This blog post details all the steps, if ever others want to go the same road.
Flatpak Installation
Disclaimer: this section is hardly anything more than a copy/paste of the
official documentation, and with time it
will get outdated, so you'd better follow the official doc.
And that's all there is to it! Now come the optional steps.
For GNOME and KDE users, you might want to install a plugin for the software
manager specific to your desktop, so that it can support and manage Flatpak
apps:
And here's an additional check you can do, as it's something that did bite me
in the past: missing xdg-portal-* packages, that are required for Flatpak
applications to communicate with the desktop environment. Just to be sure, you
can check the output of apt search '^xdg-desktop-portal' to see what's
available, and compare with the output of dpkg -l | grep xdg-desktop-portal.
As you can see, if you're a GNOME or KDE user, there's a portal backend for
you, and it should be installed. For reference, this is what I have on my GNOME
desktop at the moment:
This is trivial, but still, there's a question I've always asked myself: should
I install applications system-wide (aka. flatpak --system, the default) or
per-user (aka. flatpak --user)? Turns out, this questions is answered in the
Flatpak documentation:
Flatpak commands are run system-wide by default. If you are installing
applications for day-to-day usage, it is recommended to stick with this
default behavior.
Armed with this new knowledge, let's install the
Firefox app:
$flatpakinstallflathuborg.mozilla.firefox
And that's about it! We can give it a go already:
$flatpakrunorg.mozilla.firefox
Data migration
At this point, running Firefox via Flatpak gives me an "empty" Firefox. That's
not what I want, instead I want my usual Firefox, with a gazillion of tabs
already opened, a few extensions, bookmarks and so on.
As it turns out, Mozilla provides a brief doc for data
migration,
and it's as simple as moving Firefox data directory around!
To clarify, we'll be copying data:
from ~/.mozilla/ -- where the Firefox Debian package stores its data
into ~/.var/app/org.mozilla.firefox/.mozilla/ -- where the Firefox Flatpak
app stores its data
Make sure that all Firefox instances are closed, then proceed:
At this point, flatpak run org.mozilla.firefox takes me to my "usual"
everyday Firefox, with all its tabs opened, pinned, bookmarked, etc.
More integration?
After following all the steps above, I must say that I'm 99% happy. So far,
everything works as before, I didn't hit any issue, and I don't even notice
that Firefox is running via Flatpak, it's completely transparent.
So where's the 1% of unhappiness? The « Run a Command » dialog from GNOME, the
one that shows up via the keyboard shortcut <Alt+F2>. This is how I start my
GUI applications, and I usually run two Firefox instances in parallel (one for
work, one for personal), using the firefox -p <profile> command.
Given that I ran apt purge firefox before (to avoid confusing myself with two
installations of Firefox), now the right (and only) way to start Firefox from a
command-line is to type flatpak run org.mozilla.firefox -p <profile>. Typing
that every time is way too cumbersome, so I need something quicker.
Seems like the most straightforward is to create a wrapper script:
And now I can just hit <Alt+F2> and type firefox -p <profile> to start
Firefox with the profile I want, just as before. Neat!
Looking forward: system updates
I usually update my system manually every now and then, via the well-known pair
of commands:
$sudoaptupdate
$sudoaptfull-upgrade
The downside of introducing Flatpak, ie. introducing another package manager,
is that I'll need to learn new commands to update the software that comes via
this channel.
Fortunately, there's really not much to learn. From
flatpak-update(1):
flatpak update [OPTION...] [REF...]
Updates applications and runtimes. [...] If no REF is given, everything is
updated, as well as appstream info for all remotes.
Could it be that simple? Apparently yes, the Flatpak equivalent of the two apt
commands above is just:
$flatpakupdate
Going forward, my options are:
Teach myself to run flatpak update additionally to apt update, manually,
everytime I update my system.
Go crazy: let something automatically update my Flatpak apps, in my back
and without my consent.
I'm actually tempted to go for option 2 here, and I wonder if GNOME Software
will do that for me, provided that I installed gnome-software-plugin-flatpak,
and that I checked « Software Updates -> Automatic » in the Settings (which I
did).
However, I didn't find any documentation regarding what this setting really
does, so I can't say if it will only download updates, or if it will also
install it. I'd be happy if it automatically installs new version of Flatpak
apps, but at the same time I'd be very unhappy if it automatically upgrades my
Debian system...
So we'll see. Enough for today, hope this blog post was useful!
Happy to share that ulid is now
(back) on CRAN. It provides
universally unique identifiers that are lexicographically sortable,
which improves over the more well-known uuid generators.
ulid is a
neat little package put together by Bob
Rudis a few years ago. It had recently drifted off CRAN so I offered to brush it up
and re-submit it. And as tooted
earlier today, it took just over an hour to finish that (after the
lead up work I had done, including prior email with CRAN in the loop,
the repo transfer from Bob’s to my ulid repo plus of course
a wee bit of actual maintenance; see below for more).
The NEWS entry follows.
Changes in version 0.3.1
(2024-04-02)
New Maintainer
Deleted several repository files no longer used or
needed
Added .editorconfig, ChangeLog and
cleanup
Converted NEWS.md to NEWS.Rd
Simplified R/ directory to one source file
Simplified src/ removing redundant
Makevars
Added ulid() alias
Updated / edited roxygen and README.md documention
Removed vignette which was identical to README.md
Switched continuous integration to GitHub Actions
Placed upstream (header-only) library into
src/ulid/
I recently came a cross a x509 P(rivate)KI Root Certificate which had
a pathLen constrain set on the (self signed) Root Certificate.
Since that is not commonly seen I looked a bit around to get a
better understanding about how the pathLen basic constrain
should be used.
The pathLenConstraint field is meaningful only if the cA boolean is
asserted and the key usage extension, if present, asserts the
keyCertSign bit (Section 4.2.1.3). In this case, it gives the
maximum number of non-self-issued intermediate certificates that may
follow this certificate in a valid certification path
Since the Root is always self-issued it doesn't count towards the limit,
and since it's the last certificate (or the first depending on how you count)
in a chain, it's pretty much pointless to configure a pathLen constrain
directly on a Root Certificate.
Last but not least there is the awesome
x509 Limbo project
which has a
section for validating pathLen constrains.
Since the RFC 5280 based assumption is that self signed certs do not
count, they do not check a case with such a constrain on the Root itself, and what
the implementations do about it. So the assumption right now is that they
properly ignore it.
Summary: It's pointless to set the pathLen constrain on the Root Certificate, so just
don't do it.
This morning I decided to just start writing Bits from DPL and send
whatever I have by 18:00 local time. Here it is, barely proof read,
along with all it's warts and grammar mistakes! It's slightly long and
doesn't contain any critical information, so if you're not in the mood,
don't feel compelled to read it!
Get ready for a new DPL!
Soon, the voting period will start to elect our next DPL, and my time
as DPL will come to an end. Reading the questions posted to the new
candidates on debian-vote, it takes quite a bit of restraint to not
answer all of them myself, I think I can see how that aspect contributed
to me being reeled in to running for DPL! In total I've done so 5 times
(the first time I ran, Sam was elected!).
Good luck to both Andreas and Sruthi, our current
DPL candidates! I've already started working on preparing handover, and
there's multiple request from teams that have came in recently that will
have to wait for the new term, so I hope they're both ready to hit the
ground running!
Things that I wish could have gone better
Communication
Recently, I saw a t-shirt that read:
Adulthood is saying, 'But after this week things will slow down a bit'
over and over until you die.
I can relate! With every task, crisis or deadline that appears, I think
that once this is over, I'll have some more breathing space to get back
to non-urgent, but important tasks. "Bits from the DPL" was something I
really wanted to get right this last term, and clearly failed
spectacularly. I have two long Bits from the DPL drafts that I never
finished, I tend to have prioritised problems of the day over
communication. With all the hindsight I have, I'm not sure which is
better to prioritise, I do rate communication and transparency very
highly and this is really the top thing that I wish I could've done
better over the last four years.
On that note, thanks to people who provided me with some kind words
when I've mentioned this to them before. They pointed out that there
are many other ways to communicate and be in touch with the community,
and they mentioned that they thought that I did a good job with that.
Since I'm still on communication, I think we can all learn to be more
effective at it, since it's really so important for the project. Every
time I publicly spoke about us spending more money, we got more
donations. People out there really like to see how we invest funds in
to Debian, instead of just making it heap up. DSA just spent a nice
chunk on money on hardware, but we don't have very good visibility on
it. It's one thing having it on a public line item in SPI's reporting,
but it would be much more exciting if DSA could provide a write-up on
all the cool hardware they're buying and what impact it would have on
developers, and post it somewhere prominent like debian-devel-announce,
Planet Debian or Bits from Debian (from the publicity team).
I don't want to single out DSA there, it's difficult and affects many
other teams. The Salsa CI team also spent a lot of resources (time and
money wise) to extend testing on AMD GPUs and other AMD hardware. It's
fantastic and interesting work, and really more people within the
project and in the outside world should know about it!
I'm not going to push my agendas to the next DPL, but I hope that they
continue to encourage people to write about their work, and hopefully
at some point we'll build enough excitement in doing so that it becomes
a more normal part of our daily work.
Founding Debian as a standalone entity
This was my number one goal for the project this last term, which was a
carried over item from my previous terms.
I'm tempted to write everything out here, including the problem
statement and our current predicaments, what kind of ground work needs
to happen, likely constitutional changes that need to happen, and the
nature of the GR that would be needed to make such a thing happen, but
if I start with that, I might not finish this mail.
In short, I 100% believe that this is still a very high ranking issue
for Debian, and perhaps after my term I'd be in a better position to
spend more time on this (hmm, is this an instance of "The grass is
always better on the other side", or "Next week will go better until I
die?"). Anyway, I'm willing to work with any future DPL on this, and
perhaps it can in itself be a delegation tasked to properly explore
all the options, and write up a report for the project that can lead to
a GR.
Overall, I'd rather have us take another few years and do this
properly, rather than rush into something that is again difficult to
change afterwards. So while I very much wish this could've been
achieved in the last term, I can't say that I have any regrets here
either.
My terms in a nutshell
COVID-19 and Debian 11 era
My first term in 2020 started just as the COVID-19 pandemic became
known to spread globally. It was a tough year for everyone, and Debian
wasn't immune against its effects either. Many of our contributors got
sick, some have lost loved ones (my father passed away in March 2020
just after I became DPL), some have lost their jobs (or other earners
in their household have) and the effects of social distancing took a
mental and even physical health toll on many. In Debian, we tend to do
really well when we get together in person to solve problems, and when
DebConf20 got cancelled in person, we understood that that was
necessary, but it was still more bad news in a year we had too much of
it already.
I can't remember if there was ever any kind of formal choice or
discussion about this at any time, but the DebConf video team just kind
of organically and spontaneously became the orga team for an online
DebConf, and that lead to our first ever completely online DebConf. This
was great on so many levels. We got to see each other's faces again,
even though it was on screen. We had some teams talk to each other face
to face for the first time in years, even though it was just on a Jitsi
call. It had a lasting cultural change in Debian, some teams still have
video meetings now, where they didn't do that before, and I think it's a
good supplement to our other methods of communication.
We also had a few online Mini-DebConfs that was fun, but DebConf21 was
also online, and by then we all developed an online conference fatigue,
and while it was another good online event overall, it did start to
feel a bit like a zombieconf and after that, we had some really nice
events from the Brazillians, but no big global online community events
again. In my opinion online MiniDebConfs can be a great way to develop
our community and we should spend some further energy into this, but
hey! This isn't a platform so let me back out of talking about the
future as I see it...
Despite all the adversity that we faced together, the Debian 11 release
ended up being quite good. It happened about a month or so later than
what we ideally would've liked, but it was a solid release nonetheless.
It turns out that for quite a few people, staying inside for a few
months to focus on Debian bugs was quite productive, and Debian 11 ended
up being a very polished release.
During this time period we also had to deal with a previous Debian
Developer that was expelled for his poor behaviour in Debian, who
continued to harass members of the Debian project and in other free
software communities after his expulsion. This ended up being quite a
lot of work since we had to take legal action to protect our community,
and eventually also get the police involved. I'm not going to give him
the satisfaction by spending too much time talking about him, but you
can read our official statement regarding Daniel Pocock here:
https://www.debian.org/News/2021/20211117
In late 2021 and early 2022 we also discussed our general resolution
process, and had two consequent votes to address some issues that have
affected past votes:
In my first term I addressed our delegations that were a bit behind, by
the end of my last term all delegation requests are up to date. There's
still some work to do, but I'm feeling good that I get to hand this
over to the next DPL in a very decent state. Delegation updates can be
very deceiving, sometimes a delegation is completely re-written and it
was just 1 or 2 hours of work. Other times, a delegation updated can
contain one line that has changed or a change in one team member that
was the result of days worth of discussion and hashing out differences.
I also received quite a few requests either to host a service, or to
pay a third-party directly for hosting. This was quite an admin
nightmare, it either meant we had to manually do monthly reimbursements
to someone, or have our TOs create accounts/agreements at the multiple
providers that people use. So, after talking to a few people about
this, we founded the DebianNet team (we could've admittedly chosen a
better name, but that can happen later on) for providing hosting at two
different hosting providers that we have agreement with so that people
who host things under debian.net have an easy way to host it, and then
at the same time Debian also has more control if a site maintainer goes
MIA.
You might notice some Openstack mentioned there, we had some intention
to set up a Debian cloud for hosting these things, that could also be
used for other additional Debiany things like archive rebuilds, but
these have so far fallen through. We still consider it a good idea and
hopefully it will work out some other time (if you're a large company
who can sponsor few racks and servers, please get in touch!)
DebConf22 and Debian 12 era
DebConf22 was the first time we returned to an in-person DebConf. It
was a bit smaller than our usual DebConf - understandably so,
considering that there were still COVID risks and people who were at
high risk or who had family with high risk factors did the sensible
thing and stayed home.
After watching many MiniDebConfs online, I also attended my first ever
MiniDebConf in Hamburg. It still feels odd typing that, it feels like I
should've been at one before, but my location makes attending them
difficult (on a side-note, a few of us are working on bootstrapping a
South African Debian community and hopefully we can pull off
MiniDebConf in South Africa later this year).
While I was at the MiniDebConf, I gave a talk where I covered the
evolution of firmware, from the simple e-proms that you'd find in old
printers to the complicated firmware in modern GPUs that basically
contain complete operating systems- complete with drivers for the
device their running on. I also showed my shiny new laptop, and
explained that it's impossible to install that laptop without non-free
firmware (you'd get a black display on d-i or Debian live). Also that
you couldn't even use an accessibility mode with audio since even that
depends on non-free firmware these days.
Steve, from the image building team, has said for a while that we need
to do a GR to vote for this, and after more discussion at DebConf, I
kept nudging him to propose the GR, and we ended up voting in favour of
it. I do believe that someone out there should be campaigning for more
free firmware (unfortunately in Debian we just don't have the resources
for this), but, I'm glad that we have the firmware included. In the
end, the choice comes down to whether we still want Debian to be
installable on mainstream bare-metal hardware.
At this point, I'd like to give a special thanks to the ftpmasters,
image building team and the installer team who worked really hard to
get the changes done that were needed in order to make this happen for
Debian 12, and for being really proactive for remaining niggles that
was solved by the time Debian 12.1 was released.
The included firmware contributed to Debian 12 being a huge success,
but it wasn't the only factor. I had a list of personal peeves, and as
the hard freeze hit, I lost hope that these would be fixed and made
peace with the fact that Debian 12 would release with those bugs. I'm
glad that lots of people proved me wrong and also proved that it's
never to late to fix bugs, everything on my list got eliminated by the
time final freeze hit, which was great! We usually aim to have a
release ready about 2 years after the previous release, sometimes there
are complications during a freeze and it can take a bit longer. But due
to the excellent co-ordination of the release team and heavy lifting
from many DDs, the Debian 12 release happened 21 months and 3 weeks
after the Debian 11 release. I hope the work from the release team
continues to pay off so that we can achieve their goals of having
shorter and less painful freezes in the future!
Even though many things were going well, the ongoing usr-merge effort
highlighted some social problems within our processes. I started typing
out the whole history of usrmerge here, but it's going to be too long
for the purpose of this mail. Important questions that did come out of
this is, should core Debian packages be team maintained? And also about
how far the CTTE should really be able to override a maintainer. We had
lots of discussion about this at DebConf22, but didn't make much
concrete progress. I think that at some point we'll probably have a GR
about package maintenance. Also, thank you to Guillem who very
patiently explained a few things to me (after probably having have to
done so many times to others before already) and to Helmut who have
done the same during the MiniDebConf in Hamburg. I think all the
technical and social issues here are fixable, it will just take some
time and patience and I have lots of confidence in everyone involved.
DebConf23 took place in Kochi, India. At the end of my Bits from the
DPL talk there, someone asked me what the most difficult thing I had to
do was during my terms as DPL. I answered that nothing particular stood
out, and even the most difficult tasks ended up being rewarding to work
on. Little did I know that my most difficult period of being DPL was
just about to follow. During the day trip, one of our contributors,
Abraham Raji, passed away in a tragic accident. There's really not
anything anyone could've done to predict or stop it, but it was
devastating to many of us, especially the people closest to him. Quite
a number of DebConf attendees went to his funeral, wearing the DebConf
t-shirts he designed as a tribute. It still haunts me when I saw his
mother scream "He was my everything! He was my everything!", this was
by a large margin the hardest day I've ever had in Debian, and I really
wasn't ok for even a few weeks after that and I think the hurt will be
with many of us for some time to come. So, a plea again to everyone,
please take care of yourself! There's probably more people that love
you than you realise.
A special thanks to the DebConf23 team, who did a really good job
despite all the uphills they faced (and there were many!).
As DPL, I think that planning for a DebConf is near to impossible, all
you can do is show up and just jump into things. I planned to work with
Enrico to finish up something that will hopefully save future DPLs some
time, and that is a web-based DD certificate creator instead of having
the DPL do so manually using LaTeX. It already mostly works, you can
see the work so far by visiting
https://nm.debian.org/person/ACCOUNTNAME/certificate/ and replacing
ACCOUNTNAME with your Debian account name, and if you're a DD, you
should see your certificate. It still needs a few minor changes and a
DPL signature, but at this point I think that will be finished up when
the new DPL start. Thanks to Enrico for working on this!
Since my first term, I've been trying to find ways to improve all our
accounting/finance issues. Tracking what we spend on things, and
getting an annual overview is hard, especially over 3 trusted
organisations. The reimbursement process can also be really tedious,
especially when you have to provide files in a certain order and
combine them into a PDF. So, at DebConf22 we had a meeting along with
the treasurer team and Stefano Rivera who said that it might be
possible for him to work on a new system as part of his Freexian work.
It worked out, and Freexian funded the development of the system since
then, and after DebConf23 we handled the reimbursements for the
conference via the new reimbursements site:
https://reimbursements.debian.net/
It's still early days, but over time it should be linked to all our TOs
and we'll use the same category codes across the board. So, overall,
our reimbursement process becomes a lot simpler, and also we'll be able
to get information like how much money we've spent on any category in
any period. It will also help us to track how much money we have
available or how much we spend on recurring costs. Right now that needs
manual polling from our TOs. So I'm really glad that this is a big
long-standing problem in the project that is being fixed.
For Debian 13, we're waving goodbye to the KFreeBSD and mipsel ports.
But we're also gaining riscv64 and loongarch64 as release
architectures! I have 3 different RISC-V based machines on my desk here
that I haven't had much time to work with yet, you can expect some blog
posts about them soon after my DPL term ends!
As Debian is a unix-like system, we're affected by the
Year 2038 problem, where systems that uses 32 bit time in seconds
since 1970 run out of available time and will wrap back to 1970 or have
other undefined behaviour. A detailed wiki page explains how this
works in Debian, and currently we're going through a rather large
transition to make this possible.
I believe this is the right time for Debian to be addressing this,
we're still a bit more than a year away for the Debian 13 release, and
this provides enough time to test the implementation before 2038 rolls
along.
Of course, big complicated transitions with dependency loops that
causes chaos for everyone would still be too easy, so this past weekend
(which is a holiday period in most of the west due to Easter weekend)
has been filled with dealing with an upstream bug in xz-utils, where a
backdoor was placed in this key piece of software. An Ars Technica
covers it quite well, so I won't go into all the details here. I
mention it because I want to give yet another special thanks to
everyone involved in dealing with this on the Debian side. Everyone
involved, from the ftpmasters to security team and others involved were
super calm and professional and made quick, high quality decisions.
This also lead to the archive being frozen on Saturday, this is the
first time I've seen this happen since I've been a DD, but I'm sure
next week will go better!
Looking forward
It's really been an honour for me to serve as DPL. It might well be my
biggest achievement in my life. Previous DPLs range from prominent
software engineers to game developers, or people who have done things
like complete Iron Man, run other huge open source projects and are
part of big consortiums. Ian Jackson even authored dpkg and is now
working on the very interesting tag2upload service!
I'm a relative nobody, just someone who grew up as a poor kid in South
Africa, who just really cares about Debian a lot. And, above all, I'm
really thankful that I didn't do anything major to screw up Debian for
good.
Not unlike learning how to use Debian, and also becoming a Debian
Developer, I've learned a lot from this and it's been a really valuable
growth experience for me.
I know I can't possible give all the thanks to everyone who deserves
it, so here's a big big thanks to everyone who have worked so hard and
who have put in many, many hours to making Debian better, I consider
you all heroes!
While the work to analyze the xz backdoor is in progress, several ideas have been suggested to improve the software supply chain ecosystem. Some of those ideas are good, some of the ideas are at best irrelevant and harmless, and some suggestions are plain bad. I’d like to attempt to formalize two ideas, which have been discussed before, but the context in which they can be appreciated have not been as clear as it is today.
Reproducible tarballs. The idea is that published source tarballs should be possible to reproduce independently somehow, and that this should be continuously tested and verified — preferrably as part of the upstream project continuous integration system (e.g., GitHub action or GitLab pipeline). While nominally this looks easy to achieve, there are some complex matters in this, for example: what timestamps to use for files in the tarball? I’ve brought up this aspect before.
Minimal source tarballs without generated vendor files. Most GNU Autoconf/Automake-based tarballs pre-generated files which are important for bootstrapping on exotic systems that does not have the required dependencies. For the bootstrapping story to succeed, this approach is important to support. However it has become clear that this practice raise significant costs and risks. Most modern GNU/Linux distributions have all the required dependencies and actually prefers to re-build everything from source code. These pre-generated extra files introduce uncertainty to that process.
My strawman proposal to improve things is to define new tarball format *-src.tar.gz with at least the following properties:
The tarball should allow users to build the project, which is the entire purpose of all this. This means that at least all source code for the project has to be included.
The tarballs should be signed, for example with PGP or minisign.
The tarball should be possible to reproduce bit-by-bit by a third party using upstream’s version controlled sources and a pointer to which revision was used (e.g., git tag or git commit).
The tarball should not require an Internet connection to download things.
Corollary: every external dependency either has to be explicitly documented as such (e.g., gcc and GnuTLS), or included in the tarball.
Observation: This means including all *.pogettext translations which are normally downloaded when building from version controlled sources.
The tarball should contain everything required to build the project from source using as much externally released versioned tooling as possible. This is the “minimal” property lacking today.
Corollary: This means including a vendored copy of OpenSSL or libz is not acceptable: link to them as external projects.
Open question: How about non-released external tooling such as gnulib or autoconf archive macros? This is a bit more delicate: most distributions either just package one current version of gnulib or autoconf archive, not previous versions. While this could change, and distributions could package the gnulib git repository (up to some current version) and the autoconf archive git repository — and packages were set up to extract the version they need (gnulib’s ./bootstrap already supports this via the –gnulib-refdir parameter), this is not normally in place.
Suggested Corollary: The tarball should contain content from git submodule’s such as gnulib and the necessary Autoconf archive M4 macros required by the project.
Similar to how the GNU project specify the ./configure interface we need a documented interface for how to bootstrap the project. I suggest to use the already well established idiom of running ./bootstrap to set up the package to later be able to be built via ./configure. Of course, some projects are not using the autotool ./configure interface and will not follow this aspect either, but like most build systems that compete with autotools have instructions on how to build the project, they should document similar interfaces for bootstrapping the source tarball to allow building.
If tarballs that achieve the above goals were available from popular upstream projects, distributions could more easily use them instead of current tarballs that include pre-generated content. The advantage would be that the build process is not tainted by “unnecessary” files. We need to develop tools for maintainers to create these tarballs, similar to make dist that generate today’s foo-1.2.3.tar.gz files.
I think one common argument against this approach will be: Why bother with all that, and just use git-archive outputs? Or avoid the entire tarball approach and move directly towards version controlled check outs and referring to upstream releases as git URL and commit tag or id. One problem with this is that SHA-1 is broken, so placing trust in a SHA-1 identifier is simply not secure. Another counter-argument is that this optimize for packagers’ benefits at the cost of upstream maintainers: most upstream maintainers do not want to store gettext *.po translations in their source code repository. A compromise between the needs of maintainers and packagers is useful, so this *-src.tar.gz tarball approach is the indirection we need to solve that. Update: In my experiment with source-only tarballs for Libntlm I actually did use git-archive output.
This blog post shares my thoughts on attending Kubecon and CloudNativeCon 2024 Europe in Paris. It was my third time at
this conference, and it felt bigger than last year’s in Amsterdam. Apparently it had an impact on public transport. I
missed part of the opening keynote because of the extremely busy rush hour tram in Paris.
On Artificial Intelligence, Machine Learning and GPUs
Talks about AI, ML, and GPUs were everywhere this year. While it wasn’t my main interest, I did learn about GPU resource
sharing and power usage on Kubernetes. There were also ideas about offering Models-as-a-Service, which could be cool for
Wikimedia Toolforge in the future.
This was probably the main interest for me in the event, given Wikimedia Toolforge was about to migrate away from Pod
Security Policy, and we were currently evaluating different alternatives.
In contrast to my previous attendances to Kubecon, where there were three policy agents with presence in the program
schedule, Kyverno, Kubewarden and OpenPolicyAgent (OPA), this time only OPA had the most relevant sessions.
One surprising bit I got from one of the OPA sessions was that it could work to authorize linux PAM sessions. Could this
be useful for Wikimedia Toolforge?
I attended several sessions related to authentication topics. I discovered the keycloak software, which looks very
promising. I also attended an Oauth2 session which I had a hard time following, because I clearly missed some additional
knowledge about how Oauth2 works internally.
I also attended a couple of sessions that ended up being a vendor sales talk.
This topic was also of interest to me because, again, it is a core part of Wikimedia Toolforge.
I attended a couple of sessions regarding container image builds, including topics like general best practices, image
minimization, and buildpacks. I learned about kpack, which at first sight felt like a nice simplification of how the
Toolforge build service was implemented.
I also attended a session by the Harbor project maintainers where they shared some valuable information on things
happening soon or in the future , for example:
new harbor command line interface coming soon. Only the first iteration though.
harbor operator, to install and manage harbor. Looking for new maintainers, otherwise going to be archived.
the project is now experimenting with adding support to hosting more artifacts: maven, NPM, pypi. I wonder if they will
consider hosting Debian .deb packages.
On networking
I attended a couple of sessions regarding networking.
One session in particular I paid special attention to, ragarding on network policies. They discussed new semantics being
added to the Kubernetes API.
The different layers of abstractions being added to the API, the different hook points, and override layers clearly
resembled (to me at least) the network packet filtering stack of the linux kernel (netfilter), but without the 20 (plus)
years of experience building the right semantics and user interfaces.
In general, I believe I learned many things, and perhaps even more importantly I re-learned some stuff I had forgotten
because of lack of daily exposure. I’m really happy that the cloud native way of thinking was reinforced in me, which I
still need because most of my muscle memory to approach systems architecture and engineering is from the old pre-cloud
days. That being said, I felt less engaged with the content of the conference schedule compared to last year. I don’t
know if the schedule itself was less interesting, or that I’m losing interest?
Finally, not an official track in the conference, but we met a bunch of folks from
Wikimedia Deutschland. We had a really nice time talking about how
wikibase.cloud uses Kubernetes, whether they could run in Wikimedia Cloud Services, and why
structured data is so nice.
Learning about xz and what is happening is fascinating. The scope of potential exploit is very large. The Open source software space is filled with many unmaintained and unreviewed software.
Andres Freund found that xz-utils is backdoored,
but could not (despite the otherwise excellent analysis) get quite to the bottom of what the payload actually does.
What you would hope for to be posted by others: Further analysis of the payload.
What actually gets posted by others: “systemd is bad.”
Turns out that VPS provider Vultr's
terms of service
were quietly changed some time ago to give them a "perpetual, irrevocable"
license to use content hosted there in any way, including modifying it and
commercializing it "for purposes of providing the Services to you."
This is very similar to changes that
Github made to their TOS in 2017.
Since then, Github has been
rebranded as "The world’s leading AI-powered developer platform".
The language in their TOS now clearly lets them use content stored in
Github for training AI. (Probably this is their second line of
defense if the current attempt to legitimise copyright laundering
via generative AI fails.)
Vultr is currently in damage control mode, accusing their concerned
customers of spreading "conspiracy theories"
(-- founder David Aninowsky)
and updating the TOS to remove some of the problem language.
Although it still allows them to "make derivative works",
so could still allow their AI division to scrape VPS images
for training data.
Vultr claims this was the legalese version of technical debt,
that it only ever applied to posts in a forum
(not supported by the actual TOS language) and basically
that they and their lawyers are incompetant but not malicious.
Maybe they are indeed incompetant. But even if I give them the benefit of
the doubt, I expect that many other VPS providers, especially ones
targeting non-corporate customers, are watching this closely. If Vultr is
not significantly harmed by customers jumping ship, if the latest TOS
change is accepted as good enough, then other VPS providers will know that
they can try this TOS trick too. If Vultr's AI division does well, others
will wonder to what extent it is due to having all this juicy training
data.
For small self-hosters, this seems like a good time to make sure you're
using a VPS provider you can actually trust to not be eyeing your disk
image and salivating at the thought of stripmining it for decades of
emails. Probably also worth thinking about moving to bare metal hardware,
perhaps hosted at home.
I wonder if this will finally make it worthwhile to mess around with VPS TPMs?
I recently became a maintainer of/committer to IkiWiki,
the software that powers my site. I also took over maintenance of the Debian
package. Last week I cut a new upstream point release, 3.20200202.4, and a
corresponding Debian package upload, consisting only of a handful of
low-hanging-fruit patches from other people, largely to exercise both
processes.
I've been discussing IkiWiki's maintenance situation with some other users for
a couple of years now. I've also weighed up the pros and cons of moving to a
different static-site-generator (a term that describes what IkiWiki is, but was
actually coined more recently). It turns out IkiWiki is exceptionally flexible and
powerful: I estimate the cost of moving to something modern(er) and fashionable
such as Jekyll, Hugo or Hakyll as unreasonably high, in part because they are
surprisingly rigid and inflexible in some key places.
Like most mature software, IkiWiki has a bug backlog. Over the past couple of
weeks, as a sort-of "palate cleanser" around work pieces, I've tried to triage
one IkiWiki bug per day: either upstream or in
the Debian Bug
Tracker.
This is a really lightweight task: it can be as simple as "find a bug reported in
Debian, copy it upstream, tag it upstream, mark it forwarded; perhaps taking
5-10 minutes.
Often I'll stumble across something that has already been fixed but not recorded
as such as I go.
Despite this minimal level of work, I'm quite satisfied with the cumulative
progress. It's notable to me how much my perspective has shifted by becoming a
maintainer: I'm considering everything through a different lens to that of being
just one user.
Eventually I will put some time aside to scratch some of my own itches (html5 by
default; support dark mode; duckduckgo plugin; use the details tag...) but for
now this minimal exercise is of broader use.
But VMware does not have a monopoly on virtualization software: I think that asking regulators to interfere is unnecessary and unwise, unless, of course, they wish to question the entire foundations of copyright. Which, on the other hand, could be an intriguing position that I would support...
I believe that over-reliance on a single supplier is a typical enterprise risk: in the past decade some companies have invested in developing their own virtualization infrastructure using free software, while others have decided to rely entirely on a single proprietary software vendor.
My only big concern is that many public sector organizations will continue to use VMware and pay the huge fees designed by Broadcom to extract the maximum amount of money from their customers. However, it is ultimately the citizens who pay these bills, and blaming the evil US corporation is a great way to avoid taking responsibility for these choices.
"Several CISPE members have stated that without the ability to license and use VMware products they will quickly go bankrupt and out of business."
Uptime is often considered a measure of system reliability,
an indication that the running software is stable and can be counted on.
However, this hides the insidious build-up of state throughout the system as
it runs, the slow drift from the expected to the strange.
As Nolan Lawson highlights in an excellent post entitled
Programmers are bad at managing state,
state is the most challenging part of programming.
It’s why “did you try turning it off and on again” is a classic tech support
response to any problem.
You: uptime
Me: Every machine gets rebooted at 1AM to clear the slate for maintenance, and at 3:30AM to push through any pending updates.
In addition to the problem of state, installing regular updates periodically
requires a reboot, even if the rest of the process is automated through a
tool like unattended-upgrades.
For my personal homelab, I manage a handful of different machines running
various services.
I used to just schedule a day to update and reboot all of them, but that
got very tedious very quickly.
I then moved the reboot to a cronjob,
and then recently to a systemd timer and service.
I figure that laying out my path to better management of this might help
others, and will almost certainly lead to someone telling me a better way
to do this.
UPDATE: Turns out there’s another option for better systemd cron integration.
See systemd-cron below.
Ultimately, uptime only measures the duration since you last proved you can turn the machine on and have it boot.
The first, and easiest approach, is a simple cron job.
Just adding the following line to /var/spool/cron/crontabs/root1
is enough to get your machine to reboot once a month2 on the 6th at 8:00 AM3:
0 8 6 * * reboot
I had this configured for many years and it works well.
But you have no indication as to whether it succeeds except for checking
your uptime regularly yourself.
Stage Two: Reboot systemd Timer
The next evolution of this approach for me was to use a systemd timer.
I created a regular-reboot.timer with the following contents:
[Unit]
Description=Reboot on a Regular Basis
[Timer]
Unit=regular-reboot.service
OnBootSec=1month
[Install]
WantedBy=timers.target
This timer will trigger the regular-reboot.service systemd unit
when the system reaches one month of uptime.
I’ve seen some guides to creating timer units recommend adding
a Wants=regular-reboot.service to the [Unit] section,
but this has the consequence of running that service every time it starts the
timer. In this case that will just reboot your system on startup which is
not what you want.
Care needs to be taken to use the OnBootSec directive instead of
OnCalendar or any of the other time specifications, as your system could
reboot, discover its still within the expected window and reboot again.
With OnBootSec your system will not have that problem.
Technically, this same problem could have occurred with the cronjob approach,
but in practice it never did, as the systems took long enough to come back
up that they were no longer within the expected window for the job.
I then added the regular-reboot.service:
[Unit]
Description=Reboot on a Regular Basis
Wants=regular-reboot.timer
[Service]
Type=oneshot
ExecStart=shutdown -r 02:45
You’ll note that this service is actually scheduling a specific reboot time
via the shutdown command instead of just immediately rebooting.
This is a bit of a hack needed because I can’t control when the timer
runs exactly when using OnBootSec.
This way different systems have different reboot times so that everything
doesn’t just reboot and fail all at once. Were something to fail to come
back up I would have some time to fix it, as each machine has a few hours
between scheduled reboots.
One you have both files in place, you’ll simply need to reload configuration
and then enable and start the timer unit:
# systemctl status regular-reboot.timer
● regular-reboot.timer - Reboot on a Regular Basis
Loaded: loaded (/etc/systemd/system/regular-reboot.timer; enabled; preset: enabled)
Active: active (waiting) since Wed 2024-03-13 01:54:52 EDT; 1 week 4 days ago
Trigger: Fri 2024-04-12 12:24:42 EDT; 2 weeks 4 days left
Triggers: ● regular-reboot.service
Mar 13 01:54:52 dorfl systemd[1]: Started regular-reboot.timer - Reboot on a Regular Basis.
Sidenote: Replacing all Cron Jobs with systemd Timers
More generally, I’ve now replaced all cronjobs on my personal systems with
systemd timer units, mostly because I can now actually track failures via
prometheus-node-exporter. There are plenty of ways to hack in cron support
to the node exporter, but just moving to systemd units provides both
support for tracking failure and logging,
both of which make system administration much easier when things inevitably
go wrong.
systemd-cron
An alternative to converting everything by hand, if you happen to have
a lot of cronjobs is
systemd-cron.
It will make each crontab and /etc/cron.* directory into automatic
service and timer units.
Thanks to Alexandre Detiste for letting me know about this project.
I have few enough cron jobs that I’ve already converted, but
for anyone looking at a large number of jobs to convert
you’ll want to check it out!
Stage Three: Monitor that it’s working
The final step here is confirm that these units actually work, beyond just
firing regularly.
I now have the following rule in my prometheus-alertmanager rules:
- alert: UptimeTooHigh
expr: (time() - node_boot_time_seconds{job="node"}) / 86400 > 35
annotations:
summary: "Instance Has Been Up Too Long!"
description: "Instance Has Been Up Too Long!"
This will trigger an alert anytime that I have a machine up for more than 35
days. This actually helped me track down one machine that I had forgotten to
set up this new unit on4.
Not everything needs to scale
One of the most common fallacies programmers fall into is that we will jump
to automating a solution before we stop and figure out how much time it would even save.
In taking a slow improvement route to solve this problem for myself,
I’ve managed not to invest too much time5 in worrying about this
but also achieved a meaningful improvement beyond my first approach of doing it
all by hand.
You could also add a line to /etc/crontab or drop a script into /etc/cron.monthly depending on your system. ↩
Why once a month? Mostly to avoid regular disruptions, but still be reasonably timely on updates. ↩
If you’re looking to understand the cron time format I recommend crontab guru. ↩
In the long term I really should set up something like ansible to automatically push fleetwide changes like this but with fewer machines than fingers this seems like overkill. ↩
Of course by now writing about it, I’ve probably doubled the amount of time I’ve spent thinking about this topic but oh well… ↩